
Table of contents
The “Inside the machine” series by Giuseppe Ciuni continues. In the first article, we looked at what an LLM is — a statistical text simulator that predicts the next token — along with tokenisers, RAG and the first enterprise use cases. This second article delves a step further: understanding how a neural network learns changes the way we interpret a model’s behaviour in production, and therefore how we design a reliable system.
The concepts that will be introduced in this article are as follows:
- Gradiente, loss and Learning Rate
- Autograd (automatic differentiation)
Each of these concepts explains how AI works. A CTO or founder looking to integrate AI into their company or start-up will need to address the following questions:
- Why does an AI model come up with answers that drive CTOs mad or make the employee presenting the integration to their boss anxious, hoping the system won’t go haywire during the demo?
- Why might the same model be excellent as a general-purpose chatbot but completely unsuitable for a specialised task?
Let’s take it step by step (though we’ll have to touch on a few technical details)
How a neural network learns
A neural network is a mathematical function that takes as input a sequence of words or parts of words (the concept of a token, A neural network is a mathematical function that takes as input a sequence of words or parts of words (the concept of a token is explained in the article) and produces the next element based on a probabilistic calculation.
At the start of model training, the parameters (i.e. the weights, which are the numbers that determine the behaviour of each operation) are initialised completely at random.
In fact: “The model knows nothing”
If, at this early stage, we were to ask the model to complete the sentence:
“The wheel is a…”,
its response would be purely random. It could easily return:
“The wheel is an animal”
This problem can be solved through training
Training is the process by which the model’s parameters are adjusted step by step. In effect, it is a cycle that repeats until the algorithm’s predictions align with the ‘statistical patterns’ present in the datasets used to train the model.
The gradient (a nightmare for students who have studied Mathematical Analysis)
To understand how this correction works, let’s imagine we are in the mountains and surrounded by thick fog. The only information we have is the contour of the ground beneath our feet: we can sense whether the ground is going uphill, downhill, or sloping to the right or left. Our aim is to head downhill.
If we take it one step at a time down the slope, sooner or later we’ll make it down.
In simple, non-mathematical terms, measuring this slope beneath our feet defines the gradient.
To put it in more mathematical terms: the gradient is the vector that indicates the direction of maximum slope (the steepest incline).
Since our aim is to move downwards, the model must move in the opposite direction to the ascent: towards the minimum error. This downward process is known as gradient descent.
The gradient answers the question: “If I increase this number (the parameter) slightly, does the error go up or down? By how much?”
The Loss function
The value that measures the model’s overall error is called the loss (loss function).
The loss function performs the following calculation: it takes the output generated by the model (the prediction) and mathematically measures how far it is from the correct answer (the true value).
In our example, the loss represents our altitude on the mountain.
The loss function answers the question: “How far off the mark am I at this very moment? How far are we from the minimum error (the bottom of the valley)?”
Learning Rate
Another useful parameter in the process of minimising error is the learning rate, which determines how much weight to assign to the gradient at each iteration and, consequently, how large the step the model takes between iterations should be.
The learning rate answers the question: “How long should the step we take at each juncture of the descent be, so as not to overshoot the target?”
Finding the right stride length is one of the trickiest parts of the training itself.
If the learning rate is too high, there is a risk of overshooting: the model behaves erratically, ‘jumps’ past the global minimum (the bottom of the valley) and ends up climbing back up the opposite slope. Conversely, a learning rate that is too low results in the descent being reduced to infinitesimal shifts in the parameters, slowing down the entire process and making it inefficient in terms of time and cost.
This problem is solved by an algorithm called Adam, an optimiser that dynamically calculates the step size as parameters change; it is used in many current models, including microgpt.
To sum up, the three elements that work together at every step are:
The Loss: tells us where we are (how large the current error is).
The gradient: it tells us where to go (the direction of descent to minimise error).
Il Learning Rate: ci dice quanto deve essere lungo il passo da fare in una data direzione.
Here is a visual example in the figure illustrating the parameter optimisation process.
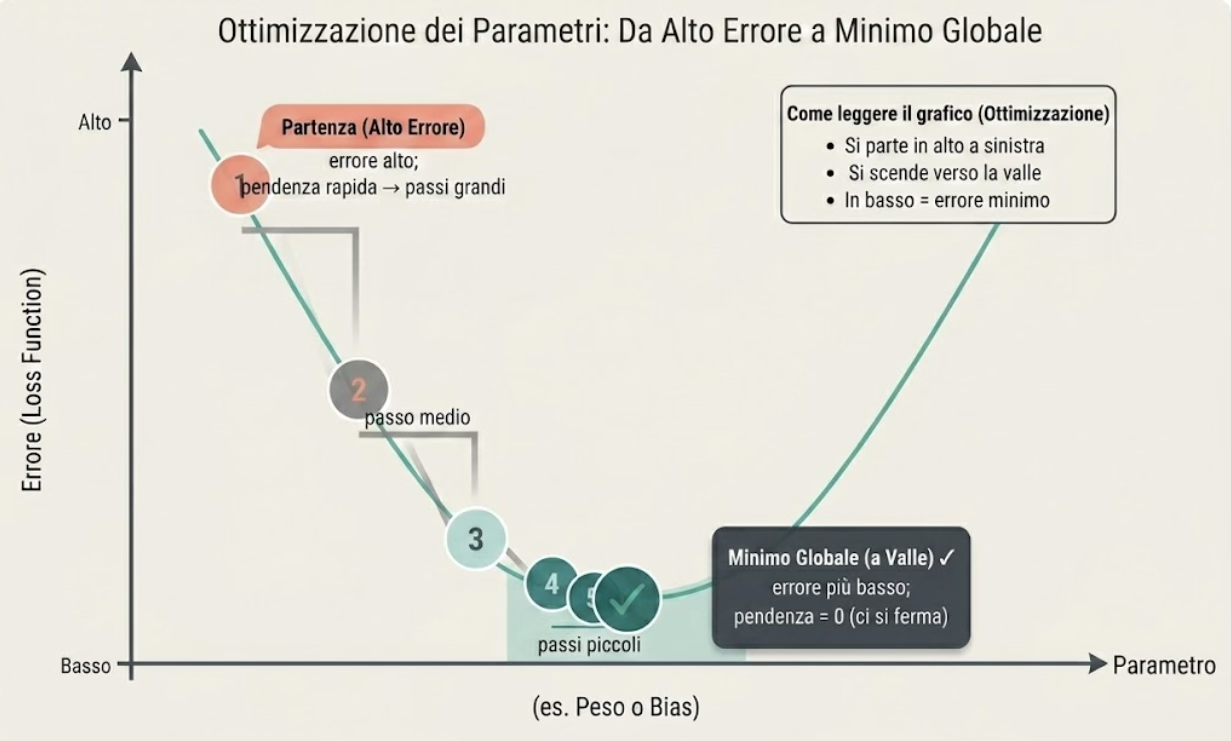
- Point 1: high error, proceed with large steps
- Point 2: error reduction; the step size is reduced
- Points 3 and 4: further reduction of the error: further reduction in the number of steps
- Point 5: trough (low point). The model makes as few errors as possible
Autograd
Whilst the model makes its prediction by attempting to guess the next token, Autograd records every single mathematical operation performed on the data, creating a detailed map of the process.
Once the final error (the loss) has been calculated using a mathematical formula, it is able to calculate the exact slope of the terrain (the gradient) for all hundreds of billions of parameters simultaneously and in a single step.
Thanks to Autograd, the entire process of calculating the gradient is automated.
Returning to the example of the mountain, given that there are hundreds of billions of parameters, what we see in the mist is not a mere human hiker but a gigantic robot made up of billions of mechanical micro-joints attempting to make its way down into the valley; see Figure 2.
Each parameter corresponds to one of these joints: the angle of a bolt on the little toe, the flexion of a knee joint, the tilt of a vertebra, and so on.
At first, as the settings are random, the robot moves in an uncoordinated manner. To descend, it must adjust all the billions of bolts simultaneously, based on the slope of the ground (the gradient).
Autograd calculates the gradients of the model parameters and provides a gradient map for all the robot’s joints. This allows each joint to be coordinated until the robot’s posture is suitable for running down the valley.
Figure 2 illustrates how Autograd works:
- In the first image, the robot is completely uncoordinated (random initial parameters).
- In the second image, the robot begins to coordinate its first joints (parameters currently being adjusted).
- In the third image, the robot is in its running configuration heading towards the valley (the parameter optimisation phase has been completed).
Karpathy implements autograd in Microgpt in around thirty lines of Python.

Conclusions
If those with decision-making authority within a company stop viewing AI as a ‘magic box’ and understand how it works, they will be able to anticipate the model’s failures rather than simply having to deal with them.
In this sector, it is important to bear in mind two key concepts of both an economic and a technical nature:
Tip 1: The cost of training a model
Training GPT-4 from scratch cost hundreds of millions of dollars. Training “Llama 3 70B” cost less, but still ran into the millions of dollars. It would be interesting to know how much it cost to train Claude’s Opus 4.8.
Fine-tuning an existing model costs between €500 and €10,000, depending on the size of the model and the amount of data.
99% of companies don’t need to train staff from scratch: the basic training has already been carried out and paid for.
The budget for those looking to introduce AI into their start-up or business production process is allocated to fine-tuning or RAG (if it is necessary to work with up-to-date data).
Tip 2: “The model learns from our users”
The process of tuning billions of parameters takes place once, on dedicated infrastructure with vast resources. Once a model is in production, the parameters are fixed.
The model typically does not change, does not learn, and does not update itself
If a seller of AI solutions tells you that “our model adapts to your users over time”, you need to ask the following questions: how does this happen? How often is the model retrained? On what data? Above all: who pays for it? If the answers are not comprehensive – as they likely won’t be – it means that the claim that the model adapts to users is untrue; it would be too expensive, even though with highly advanced technologies there is always the possibility, however remote, that something unexpected might happen.
The next issue of ‘Inside the Machine’ will explore the base model and the Instruct model, Supervised Fine-Tuning, and Reinforcement Learning from Human Feedback (photo by Igor Omilaev on Unsplash)
ALL RIGHTS RESERVED ©
