
Indice degli argomenti
Prosegue la serie “Inside the machine” a cura di Giuseppe Ciuni. Nel primo articolo abbiamo visto cos’è un LLM — un simulatore statistico di testo che prevede il prossimo token — con tokenizer, RAG e i primi casi d’uso aziendali. Questo secondo articolo entra un livello più in profondità: capire come una rete neurale impara cambia il modo in cui si interpreta il comportamento di un modello in produzione, e quindi come si progetta un sistema affidabile.
I concetti che verranno introdotti in questo articolo sono i seguenti:
- Gradiente, loss e Learning Rate
- Autograd (automatic differentiation)
Ognuno di questi concetti spiegano il comportamento della IA. Un CTO o un fondatore che integri l’IA presso la propria azienda o startup dovrà affrontare i seguenti quesiti:
- Perché un modello di IA inventa risposte facendo impazzire i CTO o mettendo in ansia il dipendente che presenta al proprio capo l’integrazione, sperando che il sistema non allucini durante la demo?
- Perché lo stesso modello può essere ottimo come chatbot generico e del tutto inadatto a un compito verticale?
Andiamo a piccoli passi (anche se qualche tecnicismo è d’obbligo)
Come impara una rete neurale
Una rete neurale è una funzione matematica che prende in input una sequenza di parole o parti di esse (il concetto di token, Una rete neurale è una funzione matematica che prende in input una sequenza di parole o parti di esse (il concetto di token è spiegato nell’articolo ) e produce l’elemento successivo basandosi sul calcolo probabilistico.
All’inizio dell’addestramento di un modello i parametri (i pesi cioè i numeri che determinano il comportamento di ogni operazione) sono inizializzati in modo completamente casuale.
Di fatto: “Il modello non sa nulla”
Se in questo stato embrionale chiedessimo al modello di completare la frase:
“La ruota è un…”,
la sua risposta sarebbe puramente casuale. Potrebbe tranquillamente restituire:
“La ruota è un animale“
Questo problema si risolve attraverso l’addestramento
L’addestramento è il processo attraverso il quale i parametri del modello vengono corretti un passo alla volta. Di fatto si tratta di un ciclo che si ripete finché le previsioni dell’algoritmo non si allineano ai ‘pattern statistici’ presenti nei dataset usati per l’addestramento del modello.
Il gradiente (incubo per studenti che hanno affrontato Analisi Matematica)
Per capire come avvenga questa correzione immaginiamo di essere in montagna e di essere avvolti da una nebbia fitta. L’unica informazione a nostra disposizione è la conformazione del terreno sotto i nostri piedi: possiamo percepire se il terreno è in salita, in discesa, inclinato a destra o a sinistra. Il nostro obiettivo è andare verso il basso.
Muovendoci un passo alla volta nel verso della pendenza prima o poi riusciremo a scendere.
In termini informali e non matematici la misurazione di questa pendenza sotto i nostri piedi definisce il gradiente.
Se vogliamo dare una definizione più matematica: il gradiente è il vettore che indica la direzione di massima pendenza (la salita più ripida).
Dato che il nostro scopo è scendere verso il basso il modello deve prendere una direzione opposta alla salita: verso l’errore minimo. Questo processo di discesa prende il nome di gradiente discendente.
Il gradiente risponde alla domanda: “Se aumento leggermente questo numero (il parametro), l’errore sale o scende? Di quanto?”.
La funzione Loss
Il valore che misura l’errore complessivo del modello viene chiamato loss (funzione di perdita).
La funzione loss effettua il seguente calcolo: prende la risposta generata dal modello (la previsione) e misura matematicamente quanto sia distante dalla risposta corretta (la verità).
Nel nostro esempio la loss rappresenta la nostra altitudine sulla montagna.
La funzione loss risponde alla domanda: “Quanto sto sbagliando in questo preciso momento? Quanto siamo distanti dal minimo errore (dal fondo della valle)?”.
Il Learning Rate
Un ulteriore parametro utile nel percorso della riduzione dell’errore è il Learning Rate il quale stabilisce quanta importanza dare al gradiente ad ogni iterazione e quindi quanto deve essere lungo il passo che il modello compie tra un’iterazione e l’altra.
Il learning rate risponde alla domanda: “Quanto deve essere lungo il passo che facciamo a ogni bivio della discesa per non scavalcare la meta?”
Trovare il valore giusto del passo è una delle parti più delicate dell’addestramento stesso.
Se il learning rate è troppo alto si rischia un effetto di overshooting: il modello si muove in modo instabile, ‘salta’ oltre il minimo globale (fondo della valle) e finisce per risalire la sponda opposta. Un passo troppo piccolo invece riduce la discesa a spostamenti infinitesimali dei parametri rallentando tutto il processo e rendendolo inefficiente dal punto di vista di tempi e costi.
Questo problema viene risolto da un l’algoritmo chiamato Adam, ottimizzatore che calcola dinamicamente l’ampiezza dei passi al variare dei parametri il quale è utilizzato in molti modelli attuali compreso microgpt .
Ricapitolando, i tre elementi che lavorano insieme a ogni passo sono:
Il Loss: ci dice dove siamo (quanto è grande l’errore attuale).
Il Gradiente: ci dice dove andare (la direzione della discesa per ridurre l’errore).
Il Learning Rate: ci dice quanto deve essere lungo il passo da fare in una data direzione.
Ecco un esempio visivo in figura di processo di ottimizzazione dei parametri.
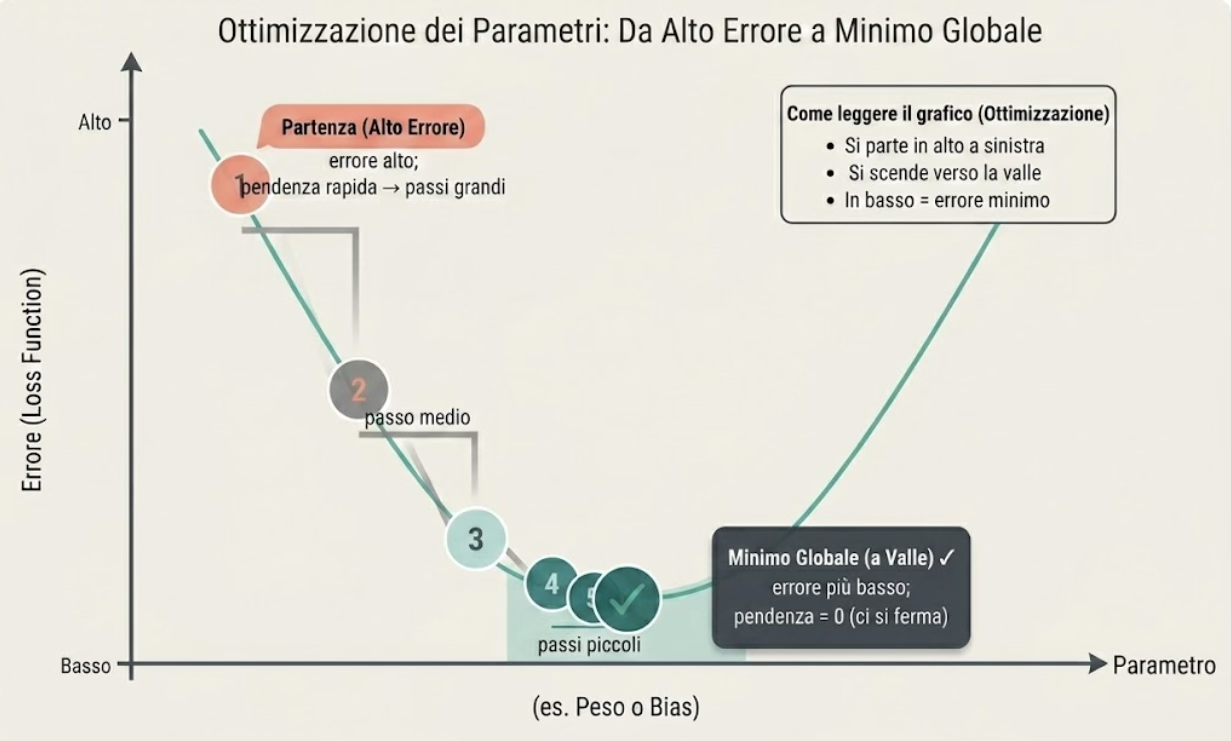
- Punto 1: errore alto, si procede con passi grandi
- Punti 2: riduzione errore, si riduce la dimensione del passo
- Punti 3,4: ulteriore riduzione dell’errore: riduzione ulteriore dei passi
- Punto 5: toccata valle (punto di minimo). Il modello sbaglia il meno possibile
Autograd
Mentre il modello fa la sua previsione provando a indovinare il token successivo, autograd registra ogni singola operazione matematica compiuta dai dati, creando una mappa dettagliata del percorso.
Una volta calcolato l’errore finale a valle (la loss) grazie ad una regola matematica, riesce a calcolare la pendenza esatta del terreno (il gradiente) per tutte le centinaia di miliardi di parametri contemporaneamente e in un colpo solo.
Grazie ad autograd, l’intero processo di calcolo della pendenza viene automatizzato.
Tornando nell’esempio della montagna, dato che i parametri sono centinaia di miliardi, in mezzo alla nebbia non c’è un semplice escursionista umano ma un gigantesco robot composto da miliardi di micro-articolazioni meccaniche che tenta di scendere a valle, vedi figura 2.
Ogni parametro è una di queste giunture: l’angolazione di un bullone sul mignolo del piede, la flessione di un pistone del ginocchio, l’inclinazione di una vertebra ecc.
All’inizio essendo i parametri regolati a caso il robot risulta scoordinato. Per scendere deve regolare contemporaneamente tutti i miliardi di bulloni basandosi sulla pendenza del terreno (il gradiente).
Autograd calcola i gradienti dei parametri del modello e fornisce la mappa della pendenza a tutte le giunture del robot. Questo permette di coordinare ogni articolazione finché la postura del robot non diventa buona per correre giù in valle.
La figura 2 rappresenta il comportamento di Autograd:
- Nella prima immagine il robot è totalmente scoordinato (parametri iniziali casuali).
- Nella seconda immagine il robot inizia a coordinare le prime giunture (parametri in fase di correzione).
- Nella terza immagine il robot è in assetto da corsa verso la valle (raggiunta fase di ottimizzazione dei parametri).
Karpathy implementa l’autograd in Microgpt in una trentina di righe di Python.

Conclusioni
Se chi ha capacità decisionale in azienda smette di guardare all’IA come a una “scatola magica” e capisce il suo funzionamento allora può riuscire ad anticipare i fallimenti del modello invece di subirli.
In questo settore bisogna tenere a mente due concetti chiave di natura sia economica che tecnica:
Hint 1: costo di addestramento di un modello
Addestrare GPT-4 da zero è costata una cifra nell’ordine di centinaia di milioni di dollari. Addestrare “Llama 3 70B” è costata meno ma sempre nell’ordine di milioni di dollari. Sarebbe interessante sapere il costo di addestramento di Opus 4.8 di Claude.
Un fine-tuning su un modello già esistente costa tra 500 e 10mila euro a seconda della dimensione del modello e della quantità di dati.
Il 99% delle aziende non deve addestrare nulla da zero: l’addestramento base è già stato fatto e pagato.
Il budget per chi deve introdurre una AI nella propria startup o processo produttivo aziendale va sul fine-tuning o sul RAG (nel caso sia necessario lavorare su dati aggiornati).
Hint 2: “il modello impara dai nostri utenti”
Il processo di regolazione dei miliardi di parametri avviene una volta, su infrastruttura dedicata con risorse enormi. Quando un modello è in produzione i parametri sono congelati.
Il modello tipicamente non cambia, non impara, non si aggiorna
Se un venditore di soluzioni IA vi dice che “il nostro modello si adatta ai tuoi utenti nel tempo” bisogna porre le seguenti domande: come avviene ciò? Quanto spesso viene riaddestrato il modello? Su quali dati? Soprattutto: chi paga? Se le risposte non sono esaustive, come è probabile non lo siano, significa che non è vero che il modello si adatti agli utenti, sarebbe troppo costoso anche se quando si tratta di tecnologie molto avanzate c’è sempre la possibilità, seppur remota, che arrivi qualcosa di inatteso.
Nel prossimo numero di ‘Inside the machine’ si illustrerà il modello base e il modello Instruct, Supervised Fine-Tuning, Il Reinforcement Learning from Human Feedback (foto di Igor Omilaev su Unsplash)
© RIPRODUZIONE RISERVATA

