
Indice degli argomenti
Prosegue la serie “Inside the machine” a cura di Giuseppe Ciuni. Nel primo articolo abbiamo visto cos’è un LLM — un simulatore statistico di testo che prevede il prossimo token — con tokenizer, RAG e i primi casi d’uso aziendali. Nel secondo articolo abbiamo visto come una rete neurale impara: loss, gradiente, learning rate, Adam e autograd. Questo terzo articolo risponde alla domanda rimasta aperta: su cosa opera esattamente il modello? Non su parole. Su vettori.
I concetti che verranno introdotti in questo articolo sono i seguenti:
- Embedding (la rappresentazione vettoriale dei token)
- Positional encoding (come il modello conosce l’ordine delle parole)
- Self-attention (come il modello collega i token tra loro)
- Multi-head attention (più letture parallele dello stesso testo)
Ognuno di questi concetti spiega un comportamento concreto del modello in produzione. Un CTO o un fondatore che integri l’IA nella propria azienda dovrà prima o poi rispondere a domande come queste:
- Perché un modello eccellente in inglese performa peggio in italiano, o sulla terminologia tecnica di settore?
- Perché allungare il contesto fa esplodere i costi?
- Perché lo stesso modello capisce che il “calcio” di una partita e il “calcio” che fa bene alle ossa sono due cose diverse?
Andiamo, come sempre, a piccoli passi.
Dall’articolo precedente, dove eravamo rimasti
Nell’Articolo 2 abbiamo lasciato il modello in addestramento: la loss misura l’errore, il gradiente indica la direzione di correzione, Adam aggiusta i parametri passo dopo passo. Ma una domanda è rimasta senza risposta: su cosa opera la rete neurale?
Sui token come numeri interi? No, e capire perché è il punto di partenza.
Ricordiamo cosa fa il tokenizer (lo abbiamo introdotto nell’articolo 1): spezza il testo in pezzi – i token – e a ogni pezzo assegna un numero pescandolo da un vocabolario fisso.
È come un grande dizionario in cui ogni voce ha una posizione: “gatto” è la voce numero 4821, “pizza” la 4822, “felino” la 7980, e così via.
Il testo, dopo il tokenizer, non è più fatto di parole ma di una sequenza di questi numeri, vedi figura in basso:
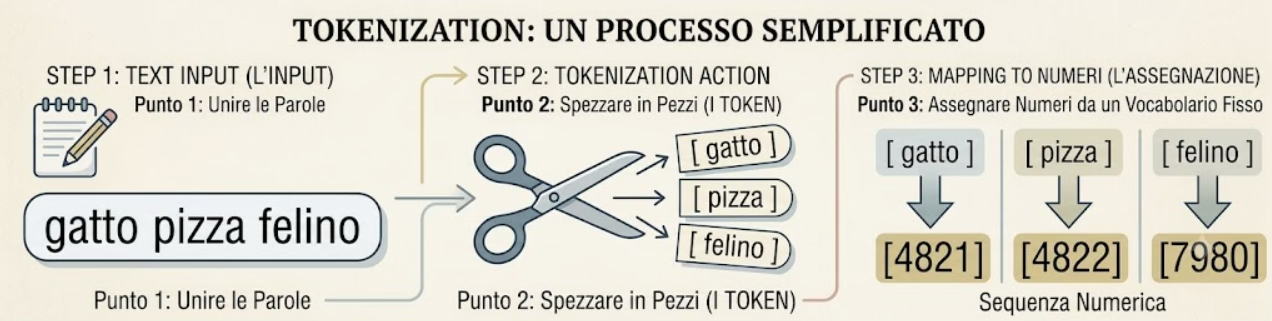
Figura 1. Il tokenizer in tre passi: prende il testo, lo spezza in pezzi (i token) e assegna a ciascuno un numero da un vocabolario fisso. Il risultato è una sequenza numerica al posto delle parole.
Il problema è che quel numero è solo un’etichetta, non una misura. È come il numero di maglia di un calciatore: serve a identificarlo ma non dice nulla su che giocatore sia. La maglia numero 10 e la numero 11 sono vicine, ma non per questo i due giocatori si somigliano.
Vale esattamente lo stesso per i token.
“Gatto” (4821) e “pizza” (4822) hanno numeri consecutivi ma non c’entrano nulla l’uno con l’altro: si sono trovati vicini per puro caso, come due parole adiacenti in ordine alfabetico.
Al contrario “gatto” (4821) e “felino” (7980) sono concetti vicinissimi ma i loro numeri sono lontanissimi, vedi esempio in figura 2.
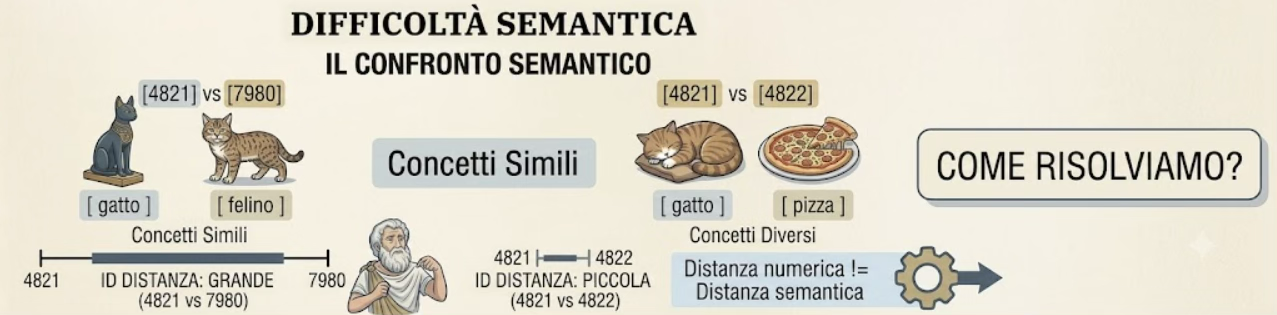
Figura 2: La distanza tra i numeri dei token non dice nulla sul significato: “gatto” (4821) e “felino” (7980) sono vicini di senso ma lontani di numero, mentre “gatto” (4821) e “pizza” (4822) sono numeri quasi uguali ma concetti diversi
In altre parole: la distanza tra i numeri non ha alcun rapporto con la distanza tra i significati. L’indice (il numero) identifica il token ma non porta con sé nessuna informazione su cosa quel token voglia dire.
Una rete neurale lavora calcolando distanze somme e relazioni tra numeri. Dopo quello che ci siamo detti, serve una conversione più ricca e che trasformi ogni token in qualcosa che codifichi davvero il significato.
Quella conversione si chiama embedding.
Embedding
Ogni token, una volta convertito in indice dal tokenizer, viene trasformato in un vettore: una lista di numeri in uno spazio ad alta dimensione.
Nei modelli moderni questo spazio ha tipicamente 768, 1.024 o anche 4.096 dimensioni (l’algoritmo di embedding text-embedding-ada-002 di OpenAI, per esempio, ne usa 1.536).
La proprietà fondamentale di questi vettori non è la loro dimensione: è la loro geometria.
Durante il training il modello impara a posizionare i token in questo spazio in modo che token con significati simili stiano vicini. Non è una scelta manuale di un programmatore: emerge automaticamente dalla pressione del gradiente durante l’addestramento. Il risultato è una sorta di mappa geografica del linguaggio.
Di fatto le parole con relazioni semantiche simili formano dei cluster: “Re”, “Regina”, “Principe” finiscono vicini; “Gatto”, “Cane”, “Felino” formano un altro gruppo.
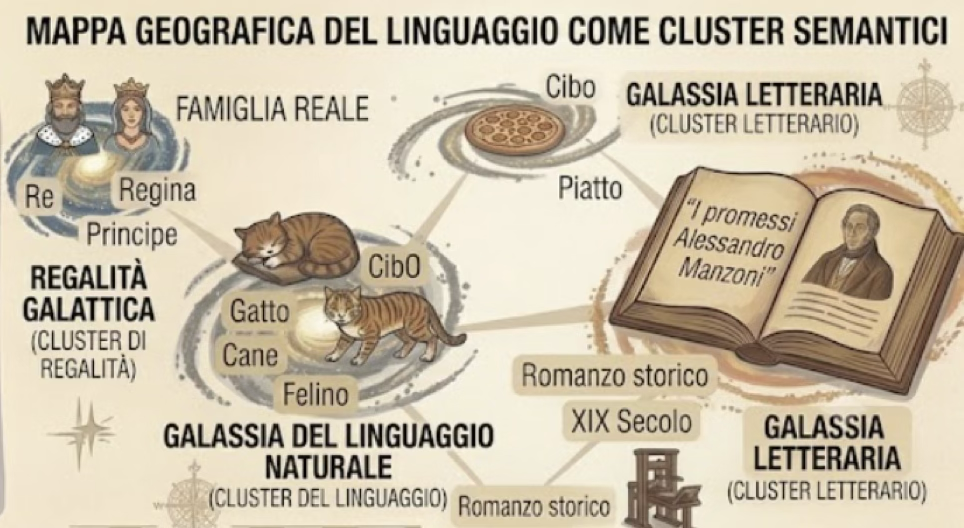
Figura 3: sono rappresentati i cluster di similitudine: il gatto, il cane, il felino appartengono ad un cluster. Il romanzo storico, I promessi sposi, pressa di Gutenberg in un altro cluster.
Una cosa interessante dei vettori è che la vicinanza non riguarda solo i sinonimi: in uno spazio ben costruito il vettore della frase “Quel ramo del lago di Como” finisce vicino a quelli di “I promessi sposi” e di “Alessandro Manzoni” perché nei testi appaiono negli stessi contesti.
Questa geometria ha una conseguenza pratica diretta. Quando si interroga un modello con “Quali località mi consiglieresti di visitare in Sicilia?” Non solo le parole della domanda vengono convertite in vettori ma il modello “sa” anche quali vettori sono vicini a “Sicilia” e usa quel contesto per costruire la risposta.
C’è infine una proprietà sorprendente: le relazioni semantiche si conservano come operazioni vettoriali. La relazione “Re − Uomo + Donna” nello spazio degli embedding produce un vettore vicino a “Regina”. (Tornano gli spazi vettoriali ed algebra lineare studiati in Geometria!)
Non è un trucco: è una proprietà emergente dell’addestramento su grandi corpora.
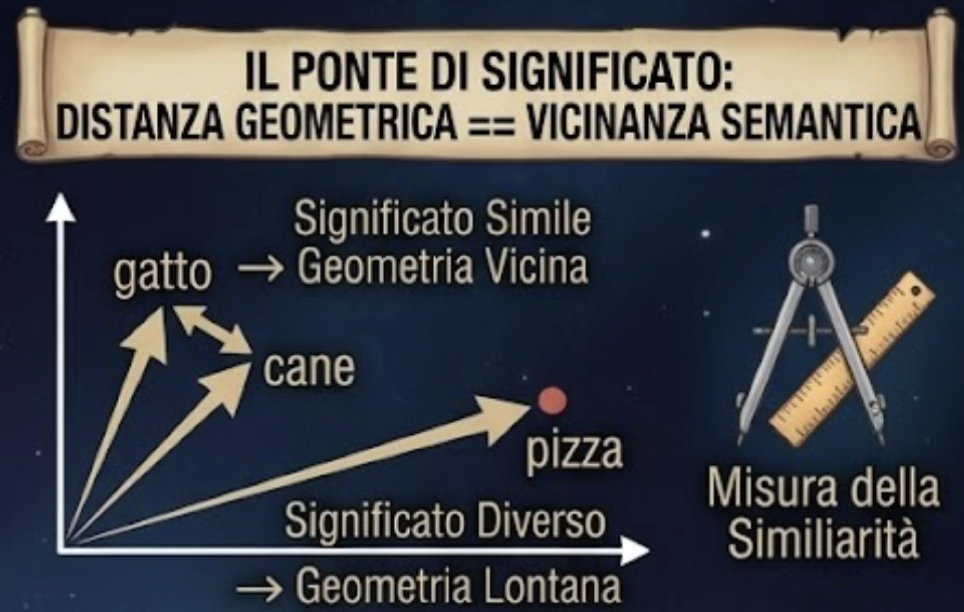
Figura 4: proiezione 2D dello spazio degli embedding — cluster semantici
Cosa sono questi vettori in pratica.
Un vettore è solo una lista di numeri: pensiamolo come la scheda di una parola. Proprio come la scheda di una persona contiene tanti dati diversi (età, altezza, città, lavoro, hobby) la scheda di un token contiene tanti numeri, e ognuno descrive un piccolo aspetto del suo significato.
E qui si capisce a cosa servono le 1.024 dimensioni: sono semplicemente 1.024 caselle, 1.024 numeri per ogni parola.
Perché così tanti? Perché un solo numero non basterebbe a catturare un significato.
Se per descrivere una persona avessi a disposizione un solo dato (poniamo l’altezza) due persone alte uguali sembrerebbero identiche pur essendo diversissime. Aggiungendo età, professione, interessi, città, riesco invece a dire in modo molto più fine quanto due persone si somiglino o differiscano.
Per le parole è lo stesso: con 1.024 numeri il modello può registrare 1.024 sfumature diverse, e così due parole possono risultare vicine sotto certi aspetti e lontane sotto altri. Un dettaglio importante: queste caselle non hanno un’etichetta decisa da noi (non c’è la casella “è un animale” o “è positivo”); è il modello a decidere da solo cosa metterci dentro.
Resta la domanda: abbiamo le etichette delle caselle, ma chi riempie i valori di tutte le caselle vere e proprie?
Nessuno a mano.
All’inizio sono piene di numeri a caso e quindi ogni parola parte in un punto qualunque della mappa, senza senso. Poi interviene il meccanismo dell’Articolo 2 .
Il modello fa un tentativo, sbaglia e misura quanto ha sbagliato (la loss). A questo punto entra in gioco la backpropagation, in parole semplici: è il procedimento con cui il modello parte dall’errore finale e torna indietro lungo tutti i calcoli che ha fatto per capire quanto ciascun numero ha contribuito allo sbaglio. Una volta capito corregge ogni numero di un pochino, nella direzione che rende l’errore più piccolo. Ripetendo questo gioco migliaia di volte, le parole che compaiono in contesti simili finiscono per avvicinarsi sulla mappa.
La geometria non è progettata ma emerge da questo continuo aggiustamento.
Ecco perché si dice che gli embedding sono pesi del modello come tutti gli altri: le caselle di ogni parola sono numeri che il training aggiusta esattamente come fa con il resto della rete. Sono solo i primi a essere creati, E sono tantissimi!
Facciamo un esempio: 50.000 parole ognuna con 1.024 caselle, fanno 50.000 × 1.024 ≈ 51 milioni di numeri. Questa tabella è letteralmente, la matrice di embedding: una riga per parola, una colonna per dimensione (vedi tabella in basso).
51 milioni di parametri spesi solo per descrivere le parole prima ancora di costruire il resto del modello: ecco spiegato il numero mostruoso di 3B di parametri per un modello, 11B per un altro etc. Ah. B sta per billion.
Facciamo un esempio di embedding delle parole cane, gatto, martello semplificando le dimensioni a 6 (non a 1024).
| è vivente? | è domestico? | è grande? | legato al cibo? | è affettivo? | è un oggetto? | |
| Gatto | 0,9 | 0,8 | −0,6 | 0,1 | 0,7 | −0,9 |
| Cane | 0,9 | 0,8 | 0,1 | 0,1 | 0,8 | −0,9 |
| martello | −0,9 | −0,8 | −0,2 | −0,3 | 0,0 | 0,9 |
Letta così, la scheda di “gatto” dice:
- molto vivente (0,9)
- molto domestico (0,8)
- piuttosto piccolo (−0,6)
- poco legato al cibo (0,1)
- affettivo (0,7)
- non è un oggetto (−0,9)
Se confrontiamo il cane con il gatto abbiamo:
“Cane” ha quasi gli stessi numeri di “gatto”: ecco perché finiscono vicini sulla mappa.
“Martello” ha numeri quasi opposti su “vivente” e “oggetto”: ecco perché finisce lontano. Questo vuol dire che parole simili hanno vettori simili: hanno liste di numeri simili.
In microgpt, il GPT in 200 righe di Karpathy tutto è ridotto all’osso: il tokenizer lavora carattere per carattere e il vocabolario sono le 26 lettere dell’alfabeto più un token speciale che segna l’inizio e la fine di ogni nome (27 token in totale). Ogni token diventa un vettore di appena 16 dimensioni. L’intero modello ha circa 4.000 parametri. È proprio questa miniaturizzazione che lo rende leggibile in un pomeriggio: la matrice di embedding è la prima cosa che viene inizializzata, e ogni riga corrisponde a un token, ogni colonna a una dimensione dello spazio semantico.
La differenza con GPT-4 è di ordini di grandezza nei numeri, ma la struttura è identica.
Positional encoding
C’è un problema che gli embedding, da soli non risolvono: la rete non sa in che ordine arrivano le parole. Per come è costruita riceve i vettori delle parole tutti insieme, come se fossero buttati in un sacchetto. Un sacchetto non ha un ordine!
Il punto è che l’ordine cambia tutto. “Il gatto mangia il topo” e “Il topo mangia il gatto” contengono le stesse identiche parole ma significano il contrario. Se la rete vede solo il sacchetto delle parole per lei le due frasi sono uguali e questo non va bene.
La soluzione si chiama positional encoding, cioè “codifica della posizione”.
L’idea è semplice: prima di dare le parole alla rete, ad ogni parola si attacca anche l’informazione su dove si trova nella frase. Di fatto oltre al vettore che dice quale parola è (l’embedding) si aggiunge un secondo vettore che dice in che posizione si trova. Così la stessa parola “gatto” riceve un segnale diverso se è la prima della frase o se è la settima.
Concettualmente è una somma:
parola_finale = vettore_della_parola + vettore_della_posizione.
I due vettori si sommano e diventano un unico vettore che è quello che entra davvero nella rete.
Un’ultima nota su microgpt: seguendo lo stile di GPT-2 le posizioni non sono calcolate con una formula fissa. Sono numeri che il modello impara da solo durante l’addestramento esattamente come impara gli embedding.
In altre parole, è il modello stesso a scoprire qual è il modo più utile per rappresentare “prima”, “seconda”, “terza” parola e così via.
Self-attention
Embedding e positional encoding sistemano la rappresentazione della singola parola. Resta il problema più difficile: il contesto.
Pensiamo alla parola “pesca”. In “ho mangiato una pesca” è un frutto; in “sono andato a pesca” è un’attività. Come si nota “pesca” è lo stesso token quindi parte con lo stesso identico embedding. Il significato corretto può emergere solo guardando le altre parole della frase. È esattamente il problema che la self-attention risolve: per ciascuna parola decide a quali altre parole conviene dare attenzione per chiarire il proprio significato in quel contesto.
Il meccanismo. A partire dal proprio embedding ogni parola genera tre vettori. Come? Moltiplicando l’embedding per tre matrici di pesi diverse, apprese durante il training come tutto il resto (per chi abbia voglia di andare sul tecnico: nel codice di Karpathy si chiamano wq, wk e wv).
I tre vettori sono leggibili come tre ruoli:
- Query (Q): “cosa sto cercando per capirmi?”. Per “pesca” nella nostra frase: “c’è vicino un verbo di movimento, o una parola legata al cibo?”
- Key (K): “che tipo di parola sono, cosa offro alle altre?”. Il cartellino di “andato” dice: “sono un verbo di movimento”.
- Value (V): “se mi danno attenzione, quale contenuto trasmetto?”. Il contenuto di “andato”: l’idea di azione, di spostamento.
Una metafora potrebbe aiutare: una fiera!
Ogni partecipante gira con:
- una domanda in testa (la query)
- un badge sul petto che dice chi è (la key)
- una cartellina di materiale da consegnare (il value)
Ognuno si ferma ai banchi il cui badge risponde alla propria domanda — e da quelli, e solo da quelli, prende il materiale.
Ne avevamo organizzata una tempo fa chiamata e osservando il comportamento della gente era proprio quello: gente che domandava, un cartellino attaccato al petto con nome e ruolo e una cartellina con materiale vario.
Da qui, tutto si svolge in tre passaggi.
1. Quanto due parole vanno d’accordo. Si prende la “domanda” della prima parola (la query) e il “cartellino” della seconda (la key), essendo entrambi numeri si moltiplicano casella per casella e si sommano i risultati.
Ne esce un solo numero: più i due elenchi si somigliano, più quel numero è alto. La moltiplicazione casella per casella premia le coppie che hanno valori alti negli stessi punti, cioè che “parlano delle stesse cose”. Questo numero è il punteggio di attenzione tra le due parole.
2. Da punteggi a percentuali. I punteggi così ottenuti vengono trasformati in percentuali che sommate su tutte le parole, fanno 100% (è il compito di una funzione chiamata softmax). In questo modo, per ogni parola sappiamo quanta attenzione dedicare a ciascuna delle altre: per esempio 70% a una, 20% a un’altra, 10% a una terza.
3. La parola si aggiorna. Ogni parola raccoglie un po’ del “contenuto” delle altre (il Value), prendendone tanto quanto dice la sua percentuale di attenzione. Chi ha ricevuto il 70% pesa molto, chi ha ricevuto il 10% quasi nulla. Il risultato è un nuovo vettore per quella parola arricchito da ciò che la circonda.
L’esempio coi numeri. Restiamo su “sono andato a pesca” e mettiamoci nei panni di “pesca”, che deve capire se è frutto o attività.
Per semplicità guardiamo solo due delle parole vicine, “andato” e “a“, e usiamo 6 caselle: “pesca” mostra la sua query, le altre il loro cartellino (la key).
| c1 | c2 | c3 | c4 | c5 | c6 | |
| Query di “pesca” | 0,9 | 0,1 | 0,0 | 0,8 | 0,2 | 0,1 |
| Key di “andato” | 0,8 | 0,0 | 0,1 | 0,9 | 0,1 | 0,0 |
| Key di “a” | 0,1 | 0,2 | 0,1 | 0,0 | 0,1 | 0,2 |
Le colonne c1–c6 sono le caselle del vettore: posizioni numerate, senza un significato leggibile una per un essere umano, per semplificarlo e capire il concetto c1 = ”quanto sono un verbo”, c2 = ”quanto parlo di cibo” ecc. Di fatto è un vettore che rappresenta la geometria della parola.
Per vedere quanto “pesca” e “andato” vanno d’accordo confrontiamo le loro due righe casella per casella.
La regola è semplice: quando tutte e due hanno un numero grande nella stessa casella, quella casella “vale tanto”.
Nel nostro caso succede nella c1 (0,9 e 0,8) e nella c4 (0,8 e 0,9): in entrambe le righe ci sono numeri alti, quindi le due parole sono molto in sintonia.
Sommando tutto, il punteggio viene alto: 1,46.
Con “a” invece non capita mai: dove “pesca” ha numeri grandi, “a” ne ha di piccoli. Le due parole non hanno nulla in comune ed il punteggio resta basso, circa 0,15.
Adesso questi punteggi diventano percentuali di attenzione: siccome 1,46 è molto più grande di 0,15, “pesca” dedica la fetta più grossa della sua attenzione ad “andato” (intorno al 75%) e solo una briciola ad “a” (circa il 10%); il resto si distribuisce sulle altre parole della frase.
A questo punto “pesca” si aggiorna prendendo soprattutto dal contenuto di “andato”, che è una parola di movimento. Così “pesca” si “colora” di azione ed il suo significato va verso l’attività (andare a pescare) e non il frutto.
In un’altra frase possibilmente avrebbe ascoltato vicini diversi e sarebbe finita dalla parte del frutto. Il contesto ha fatto il suo lavoro.
La metafora. Pensiamo a come leggiamo noi. Quando incontriamo una parola ambigua per un istante gli occhi tornano indietro sulle parole vicine che ne chiariscono il senso. Leggendo “sono andato a pesca”, è “andato” a dirci di che pesca si tratta, non “a“.
La self-attention fa esattamente questo: ogni parola “rilegge” le altre della frase soffermandosi su quelle che la aiutano a capirsi e ignorando il resto.
Facciamo un esempio grafico così si capisce meglio. Di seguito la matrice di attenzione della frase “sono andato a pesca”
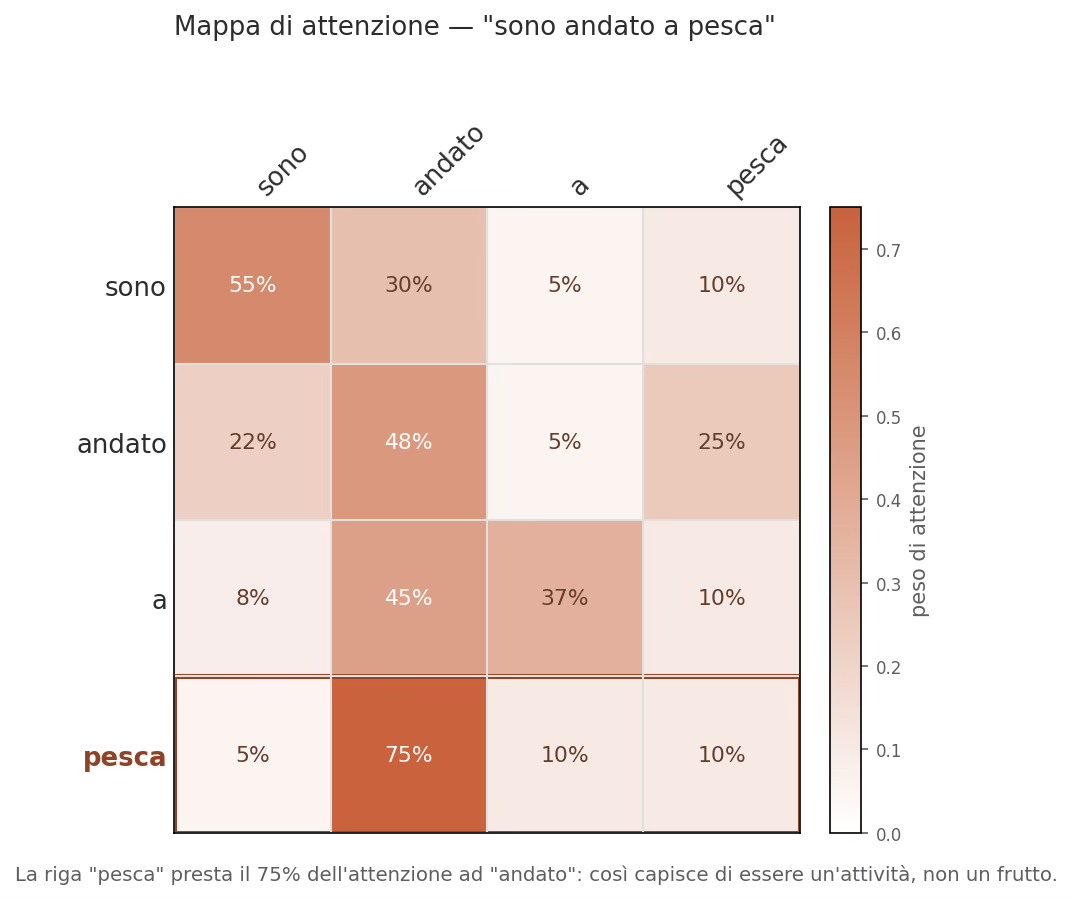
Figura 5: Matrice di attenzione di “sono andato a pesca”: ogni riga mostra quanta attenzione una parola dedica alle altre (totale 100%). La riga “pesca” presta il 75% ad “andato”, e per questo capisce di essere un’attività, non un frutto.
Come leggere questa matrice in tre passi:
- Le righe sono le parole “che guardano”. Scegli una riga: è una parola della frase mentre cerca di capirsi. La griglia ha quattro righe perché la frase ha quattro parole: “sono”, “andato”, “a”, “pesca”.
- Le colonne sono le parole “guardate” nello stesso ordine. Scorrendo una riga da sinistra a destra ogni cella dice quanta attenzione quella parola (la riga) dedica a ciascun’altra parola (la colonna).
Il numero nella cella è la percentuale di attenzione ed il colore la rende visibile meglio: più è intenso, più c’è attenzione. - Ogni riga somma 100%. L’attenzione di una parola è una “torta” divisa tra tutte le altre.
Il cuore della figura è la riga in basso: “pesca” (riquadrata con colore marroncino scuro). Si può notare dove finisce la sua attenzione: 75% su “andato” (la cella più scura), 10% su “a”, 10% su sé stessa, 5% su “sono”.
In pratica la parola “pesca” guarda soprattutto “andato” (una parola di movimento) e proprio per questo scivola verso il significato di attività (andare a pescare) e non di frutto.
La famosa frase “un’immagine vale piu di 1000 parole” è vera. Se si osserva la matrice emergono le seguenti osservazioni:
- la diagonale (sono→sono, andato→andato…) è spesso colorata perché ogni parola tiene un pò d’attenzione anche su se stessa;
- le parole “vuote” come “a” ricevono poca attenzione dalle altre , sono più chiare e contano poco per dare significato;
- se si cambiasse la frase in “ho mangiato una pesca” la riga “pesca” si illuminerebbe su “mangiato” invece che su “andato”, e il significato scivolerebbe verso il frutto. La mappa è sempre relativa a quella frase.
Multi-head attention
Una singola operazione di self-attention intuisce un tipo di legame alla volta. Ma in una frase i legami sono tanti e tutti insieme: quello grammaticale (chi è il soggetto, chi il verbo), quello di significato, quello dei riferimenti (a chi si riferisce un “lo”, un “questo”), quello temporale.
Una sola “rilettura” non basta a cogliere tutto.
La multi-head attention risolve il problema facendo più riletture in parallelo invece di una sola. Ognuna è una self-attention completa con le proprie Query, Key e Value, e può decidere di specializzarsi su un tipo di legame diverso. Ogni rilettura si chiama testa (head).
Per dare un’idea delle proporzioni: GPT-2 small ha 12 teste, in GPT-4 si stima siano nell’ordine delle centinaia. In microgpt, per semplicità, ce ne sono 4 su un unico strato di attenzione.
Riprendendo l’immagine di prima: è come rileggere la stessa frase più volte, ma ogni volta cercando una cosa diversa: una lettura segue la struttura grammaticale, un’altra le relazioni di causa-effetto, un’altra ancora capisce a quali parole si riferiscono i pronomi.
Alla fine tutte queste letture vengono rimesse insieme in un unico risultato.
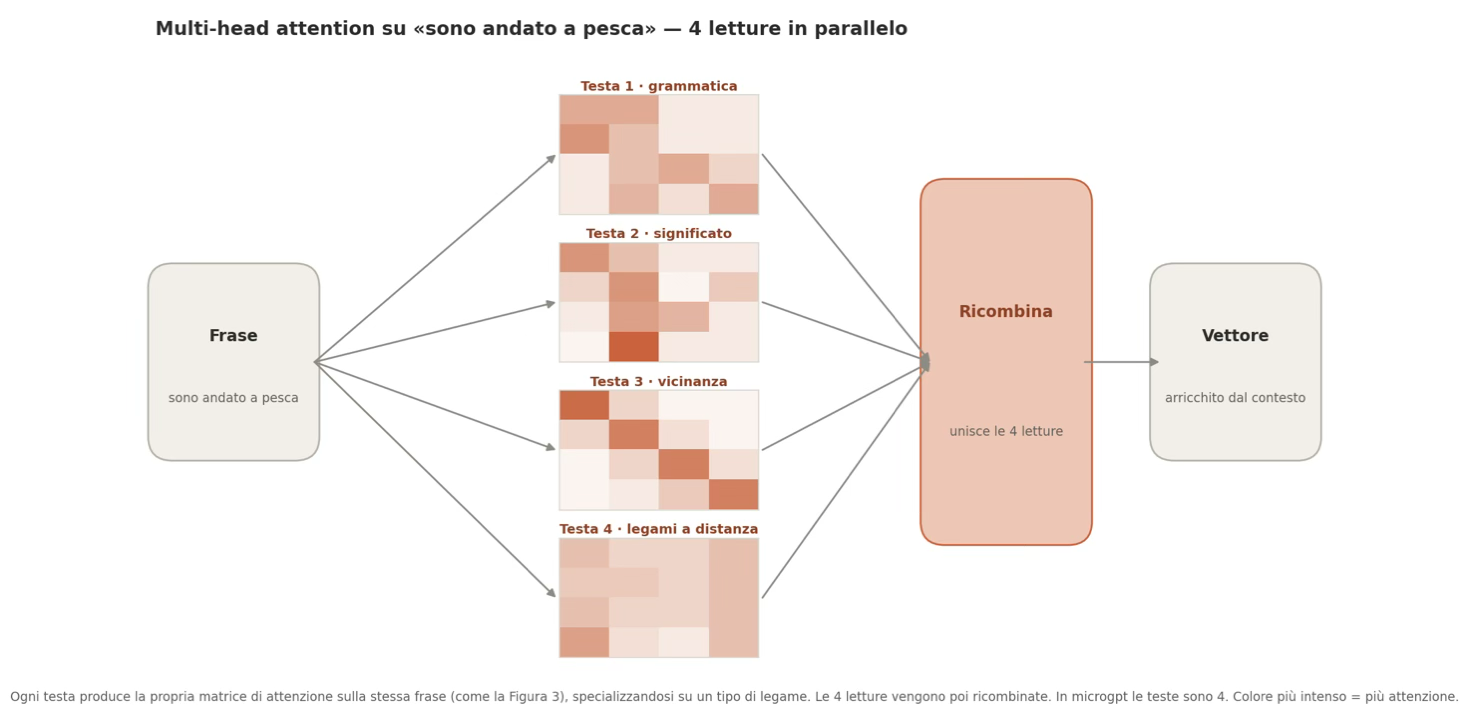
Figura 6: schema multi-head attention con più teste in parallelo per ottenere un output ricombinato
Il risultato di tutto questo è un nuovo vettore per ogni parola, arricchito dal contesto dell’intera frase. Non più un punto fisso sulla mappa del linguaggio ma un punto che si è spostato in base a ciò che lo circonda.
Cos’è il transformer
Abbiamo appena visto due meccanismi: la self-attention con cui ogni parola guarda le altre della frase e ne assorbe il contesto (è così che “pesca”, in “sono andato a pesca”, capisce di essere un’attività e non un frutto), la multi-head attention che ripete quella stessa lettura più volte in parallelo per cogliere legami diversi. Questo insieme di attività viene chiamato Transformer.
Transformer è il nome dell’architettura cioè lo schema che mette insieme nell’ordine giusto i pezzi visti finora:
- embedding
- positional encoding
- attenzione (self-attention e multi-head)
Di fatto è lo schema su cui sono costruiti tutti i modelli moderni, da GPT a Claude a Gemini. La lettera “T” di GPT sta proprio per Transformer.
Nacque nel 2017 da un articolo di Google diventato celebre, “Attention is all you need” (“L’attenzione è tutto ciò che serve”): l’idea, allora rivoluzionaria, era che per capire il linguaggio bastava l’attenzione.
Il transformer è fatto di un blocco che si ripete sempre uguale.
Dentro ogni blocco succedono due cose una dopo l’altra: prima le parole si scambiano informazioni con l’attenzione, poi ognuna rielabora da sola ciò che ha raccolto (questo è il feed-forward in basso).
La potenza dei modelli nasce dal mettere in fila tanti di questi blocchi, uno sopra l’altro. “Impilare” vuol dire collegarli in sequenza: ciò che esce dal primo blocco entra nel secondo, l’uscita del secondo entra nel terzo, e così via. Ogni blocco lavora sul risultato già raffinato dal precedente e lo migliora ancora un po’.
Vediamolo nel solito nostro esempio “sono andato a pesca”, seguendo la parola “pesca”, che parte ambigua.
Come abbiamo visto nella matrice, nel primo blocco l’attenzione le fa guardare soprattutto “andato”, e in uscita “pesca” si è già spostata verso il significato di attività.
Questo vettore, ormai più chiaro, entra nel secondo blocco che lo rifinisce ancora: per esempio coglie che “andato a pesca” è un’unica espressione, un modo di dire “andare a pescare”.
Blocco dopo blocco il significato si mette sempre più a fuoco. Ecco perché il numero di blocchi conta!
Lo schema del blocco è sempre lo stesso; cambia solo quanti se ne impilano: uno solo in microgpt, 12 in GPT-2 small, molte decine nei modelli di frontiera.
Più blocchi una parola attraversa più il modello riesce a cogliere sfumature e quindi più “capisce il senso di ciò che scriviamo”.
Microgpt ha un solo blocco forse per questioni di leggibilità (mia opinione). Mi verrebbe da usare una espressione del mio dialetto per dire: chissà quanti blocchi usa Anthropic in Fable 5 .
Gli altri ingredienti del blocco
Per leggere davvero il codice di Karpathy servono altri tre ingredienti che subito dopo l’attenzione completano il blocco. Sono meno famosi ma senza di loro il modello non si addestrerebbe.
Un’idea utile prima di partire: la rete neurale lavora a tappe come una catena di montaggio ed ogni tappa si chiama strato.
Ecco gli ingredienti:
Feed-forward. Dopo aver “ascoltato” le vicine, ogni parola rielabora da sola ciò che ha raccolto, come tornando alla scrivania. Il suo vettore viene allargato (in microgpt da 16 a 64 numeri) e poi ricompresso. Nel mezzo agisce la ReLU, un algoritmo che toglie i numeri negativi: tiene i positivi così come sono e mette a zero i negativi.
Questa piccola regola dà al calcolo una “piega” la quale serve per distinguere uno strato dall’altro in modo da poterli impilare e permettere alla rete di cogliere relazioni complesse.
Residual connection. Il risultato di ogni passaggio non sostituisce il vettore di partenza: gli si somma (x = x + correzione) come una nota a margine invece di riscrivere tutto. È ciò che permette di impilare decine di strati senza che l’informazione (il gradiente dell’Articolo 2) si perda per strada.
Normalizzazione. Prima di ogni blocco i numeri vengono riportati a una scala standard. Senza, crescerebbero o si spegnerebbero strato dopo strato rendendo l’addestramento instabile.
Embedding, Attenzione, Feed-forward, Residual connection e Normalizzazione: questo è il blocco transformer completo, il mattone che messo uno sopra l’altro in pila costruisce i modelli.
Ricapitolando
- Tokenizer: spezza il testo e attribuisce ad ogni parola un numero-etichetta (la identifica, ma non ne dice il significato).
- Embedding: trasforma quel numero in un significato collocando la parola sulla “mappa del linguaggio” ossia parole simili stanno vicine.
- Positional encoding: aggiunge l’ordine così “il gatto mangia il topo” è diverso da “il topo mangia il gatto”.
- Self-attention: ogni parola guarda le altre e si aggiorna col contesto: è così che “pesca” capisce se è frutto o attività.
- Multi-head attention: la stessa self-attention ripetuta più volte in parallelo per cogliere più tipi di legame insieme.
- Feed-forward, residual e normalizzazione: completano il blocco: rielaborano ciò che l’attenzione ha raccolto e mantengono i calcoli stabili. Sono i controllori del traffico☺
Conclusioni
Nell’Articolo 2 avevamo visto come impara il modello, in questo abbiamo scoperto su cosa lavora davvero: non su parole, non su semplici numeri usati come etichette ma su vettori ossia liste di numeri che danno a ogni parola una posizione su una “mappa del linguaggio”.
Questa mappa non la disegna un programmatore: la costruisce il modello da solo durante l’addestramento avvicinando le parole che hanno significati simili.
La posizione di una parola non è fissa e grazie all’attenzione viene aggiustata di volta in volta, a seconda della frase. In questo modo “pesca” si sposta verso il frutto o verso l’attività a seconda delle parole vicine.
Hint 1: il fine-tuning verticale parte dagli embedding
Quando un modello generico va male sulla terminologia di dominio (es. legale, manifatturiero, medicale, finanziario) il problema nasce spesso negli embedding. Termini come “letto antidecubito”, “frattura scomposta al bacino”, “insufficienza renale” erano rari o assenti nei dati di pre-training: i loro vettori sono posizionati quasi a caso e lontani dai cluster dove dovrebbero essere.
Il fine-tuning su dati di dominio corregge questa geometria.
Prima di acquistare un modello verticale “già fine-tunato” conviene chiedere al fornitore su quali dati è stato addestrato ed in che metodo. Se le risposte sono vaghe, il fine-tuning probabilmente non è stato fatto o non è stato fatto bene.
Hint 2: context window grande non significa modello migliore
I fornitori pubblicizzano context window sempre più ampie come se fossero un vantaggio lineare.
La self-attention scala in modo quadratico con la lunghezza della sequenza: raddoppiare il contesto significa quadruplicare il costo computazionale per ogni chiamata. Per applicazioni aziendali come helpdesk su basi fisse oppure classificazione documenti o estrazione da contratti bastano 4.000-8.000 token.
Scegliere un modello da 128.000 token di contesto per task del genere significa pagare tanto senza avere benefici. La context window ottimale è un parametro da misurare sui task reali e non da massimizzare a prescindere.
Notizia di un paio di giorni fa: Miglioramento ricorsivo autonomo, l’AI si auto riscrive il codice. Fonte Anthropic.
Anthropic dichiara che oltre l’80% del codice del suo codebase è stato scritto da Claude con una qualità paragonabile a quella umana. La produttività dei singoli ingegneri (misurata in linee di codice) è aumentata di 8 volte rispetto al 2024.
Nel prossimo e ultimo numero di Inside the machine chiudiamo il cerchio su microgpt. Vedremo come il vettore arricchito diventa una classifica di probabilità e come il modello genera testo un pezzo alla volta. Capiremo perché i token in uscita costano più di quelli in entrata, cosa controlla davvero la “temperatura” e qual è la differenza tra modello base e modello instruct, con i due passaggi che li separano: SFT e RLHF (foto di Igor Omilaev su Unsplash).
© RIPRODUZIONE RISERVATA
