
Indice degli argomenti
- Dove eravamo rimasti
- L'ultimo passaggio: dal vettore alla probabilità
- L'inferenza: una risposta nasce un pezzo alla volta
- Perché il modello non vede il futuro (e perché l'output costa di più)
- La temperatura: creatività o precisione
- Hint in casi pratici
- Modello base vs modello instruct
- Ricapitolando: microgpt
- Conclusioni
Prosegue la serie “Inside the machine” a cura di Giuseppe Ciuni. Nel primo articolo abbiamo visto cos’è un LLM — un simulatore statistico di testo che prevede il prossimo token — con tokenizer, RAG e i primi casi d’uso aziendali. Nel secondo articolo abbiamo visto come impara: loss, gradiente, learning rate, Adam e autograd. Nel terzo articolo abbiamo scoperto su cosa lavora: embedding, positional encoding, attention e il resto del blocco transformer. Questo quarto articolo chiude il cerchio: cosa succede quando il modello finito l’addestramento, deve davvero produrre una risposta e perché il modello che esce dal pre-training non è ancora un assistente.
I concetti che verranno introdotti in questo articolo sono i seguenti:
- lm_head (l’ultimo passaggio: dal vettore alla probabilità)
- Inferenza autoregressiva (come nasce una risposta, un pezzo alla volta)
- Causalità e KV cache (perché i token in uscita costano più di quelli in entrata)
- Temperatura (perché lo stesso prompt può dare risposte diverse)
- Modello base vs modello instruct, con i due passaggi che li separano: SFT e RLHF
Un CTO o un fondatore che integri l’IA nella propria azienda dovrà prima o poi rispondere a domande come queste:
- Perché un modello “base” scaricato da internet non risponde alle istruzioni come un assistente commerciale?
- Perché lo stesso modello a volte è “creativo” e a volte ripetitivo, e quale dei due comportamenti serve per il mio compito?
- Perché nelle fatture delle API i token in uscita costano in genere da due a cinque volte quelli in entrata?
Andiamo per piccoli passi.
Dove eravamo rimasti
L’esempio che ci accompagna dall’inizio microgpt (karpathy.ai/microgpt.html) è addestrato su un elenco di 32.000 nomi propri di persona.
Alla fine dell’addestramento non risponde a domande: genera nuovi nomi plausibili come per esempio kamon, vialan, keylen che non esistono ma “suonano” come nomi veri.
È la dimostrazione di cosa sia un LLM:
un sistema che dato un inizio produce la continuazione più coerente con ciò che ha visto.
Una cosa da dire prima di iniziare: durante l’addestramento ogni nome viene racchiuso tra due copie di un token speciale di inizio/fine sequenza (nel codice si chiama BOS, “Beginning Of Sequence”). È la ventisettesima voce del vocabolario di microgpt: 26 lettere più questo segnaposto. Il suo compito è dire al modello “qui comincia un nome” e “qui finisce un nome”. Questo fa partire e a fermare la generazione.
L’ultimo passaggio: dal vettore alla probabilità
L’Articolo 3 si è chiuso con ogni token trasformato in un vettore arricchito dal contesto. Un vettore però non è ancora una previsione, è una rappresentazione interna ossia un “riassunto” di ciò che il modello ha capito fin lì.
Per generare serve qualcosa di diverso, una classifica: quanto è probabile ciascun token del vocabolario come prossimo pezzo?
Di questa parte se ne occupa un’ultima matrice di pesi che nel codice di Karpathy che si chiama lm_head (“Language Model Head”).
Il suo lavoro è una proiezione: prende il vettore contestualizzato (16 numeri in microgpt) e lo trasforma in tanti punteggi quanti sono i token possibili (nel caso di microGPT, decine di migliaia nei modelli grandi). Questi punteggi grezzi si chiamano logit.
I logit non sono ancora percentuali: possono essere negativi, enormi, sparsi.
Ci pensa la solita softmax, la stessa identica funzione che nell’Articolo 3 trasformava i punteggi di attenzione in percentuali, a convertirli in una distribuzione di probabilità che somma a 100%.
Questo si chiama riuso del codice: la stessa funzione usata in due punti diversi per lo stesso scopo, trasformare punteggi in pesi.
Facciamo i conti su tre lettere sole.
Supponiamo che dopo “l-u-c” i logit siano: a → +2,1; o → +1,9; z → −3,5.
La softmax li trasforma in questo modo: “a” prende circa il 55%, “o” circa il 45%, “z” lo 0,2%.
Ecco cosa si nota nel comportamento: i punteggi alti e vicini restano in gara quasi alla pari, i punteggi molto bassi vengono schiacciati quasi a zero.
Come si nota questa è una classifica non una media.
La funzione di loss descritta nell’Articolo 2 usata durante l’addestramento misura proprio quanta probabilità il modello aveva assegnato in questa classifica al token giusto. Più probabilità al token corretto meno errore: è questo il numero che il gradiente lavora per abbassare (il gigante)
Una metafora: il blocco transformer è la giuria che delibera a porte chiuse
l’lm_head è il tabellone all’uscita che converte la delibera fatta dai giudici in una classifica dei candidati, ognuno con la sua percentuale. Solo a quel punto si può scegliere il vincitore.
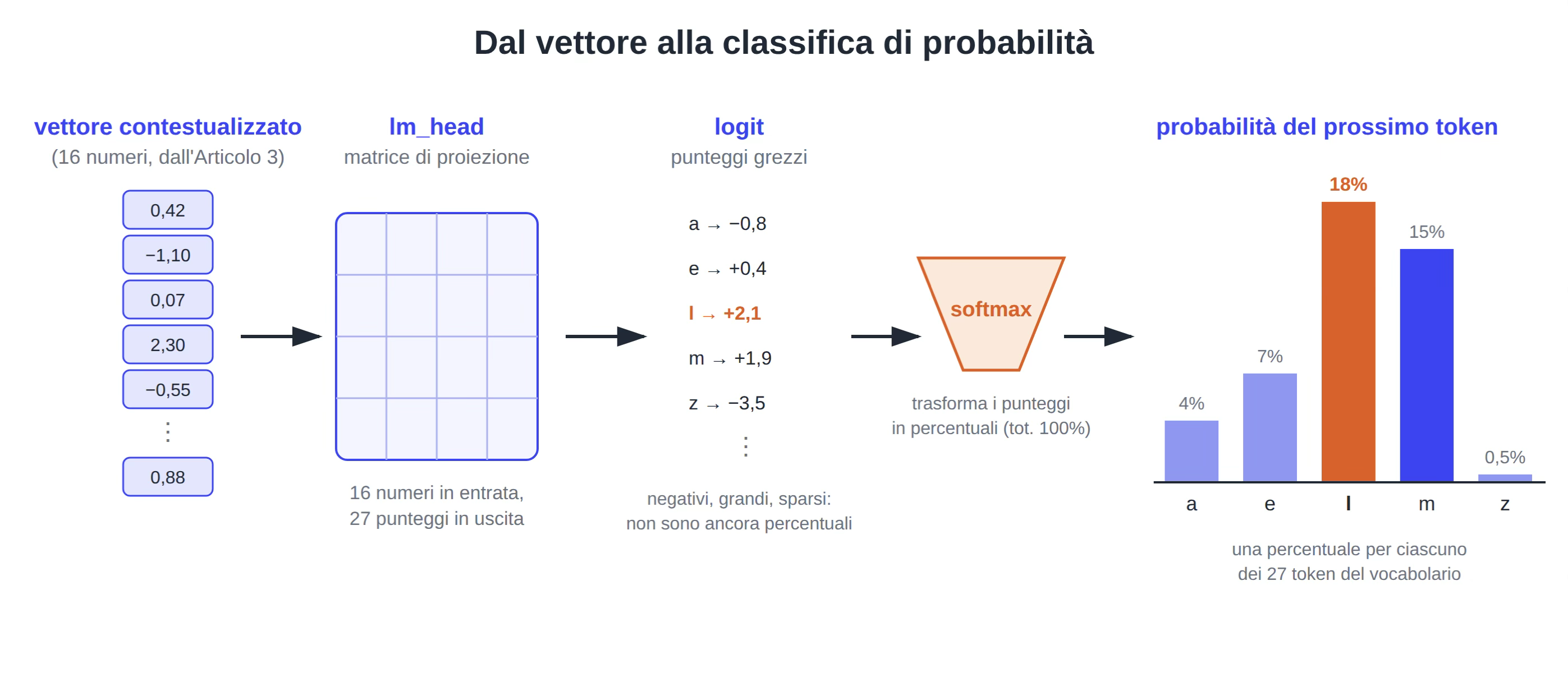
Figura 1 dal vettore contestualizzato alla classifica di probabilità: il vettore entra nella matrice lm_head, escono i logit, la softmax li trasforma in percentuali.
L’inferenza: una risposta nasce un pezzo alla volta
Da notare che addestramento e inferenza (l’uso del modello in produzione) sono due fasi diverse: durante l’addestramento i parametri vengono corretti a ogni passo, durante l’inferenza i parametri sono congelati e il modello si limita a calcolare. Il meccanismo con cui genera è sorprendentemente semplice ed è lo stesso per microgpt e per i modelli di frontiera.
È un ciclo che si ripete:
- il modello guarda quello che c’è scritto finora
- per ogni possibile pezzo successivo calcola una probabilità (è il lavoro di lm_head + softmax appena visto)
- ne sceglie uno
- lo aggiunge in fondo e ricomincia dal punto 1, stavolta con un pezzo in più.
Si va avanti così finché la frase non è completa.
Questo si chiama essere autoregressivi: ogni nuovo pezzo viene scelto guardando tutto ciò che lo precede, compreso quello che il modello stesso ha appena prodotto.
Microgpt lavora lettera per lettera.
Microgpt per inventare un nome parte dal token speciale di inizio (il BOS di prima) e si chiede: qual è la prima lettera?
Calcola le probabilità di tutte le lettere, ad esempio:l 18%, m 15%, a 12%, etc. Alla fine ne sceglie una: l.
Ora la domanda diventa: dopo “l”, quale lettera?
Magari “u”. Poi, dopo “lu”? Forse “c”. E avanti così — l → lu → luc → luca — finché il modello non ripesca proprio il token di fine sequenza: per il modello “qui il nome finisce” è una previsione come tutte le altre, imparata dai 32.000 esempi.
Come si può notare nessuna magia: a ogni passo una distribuzione di probabilità e una scelta.
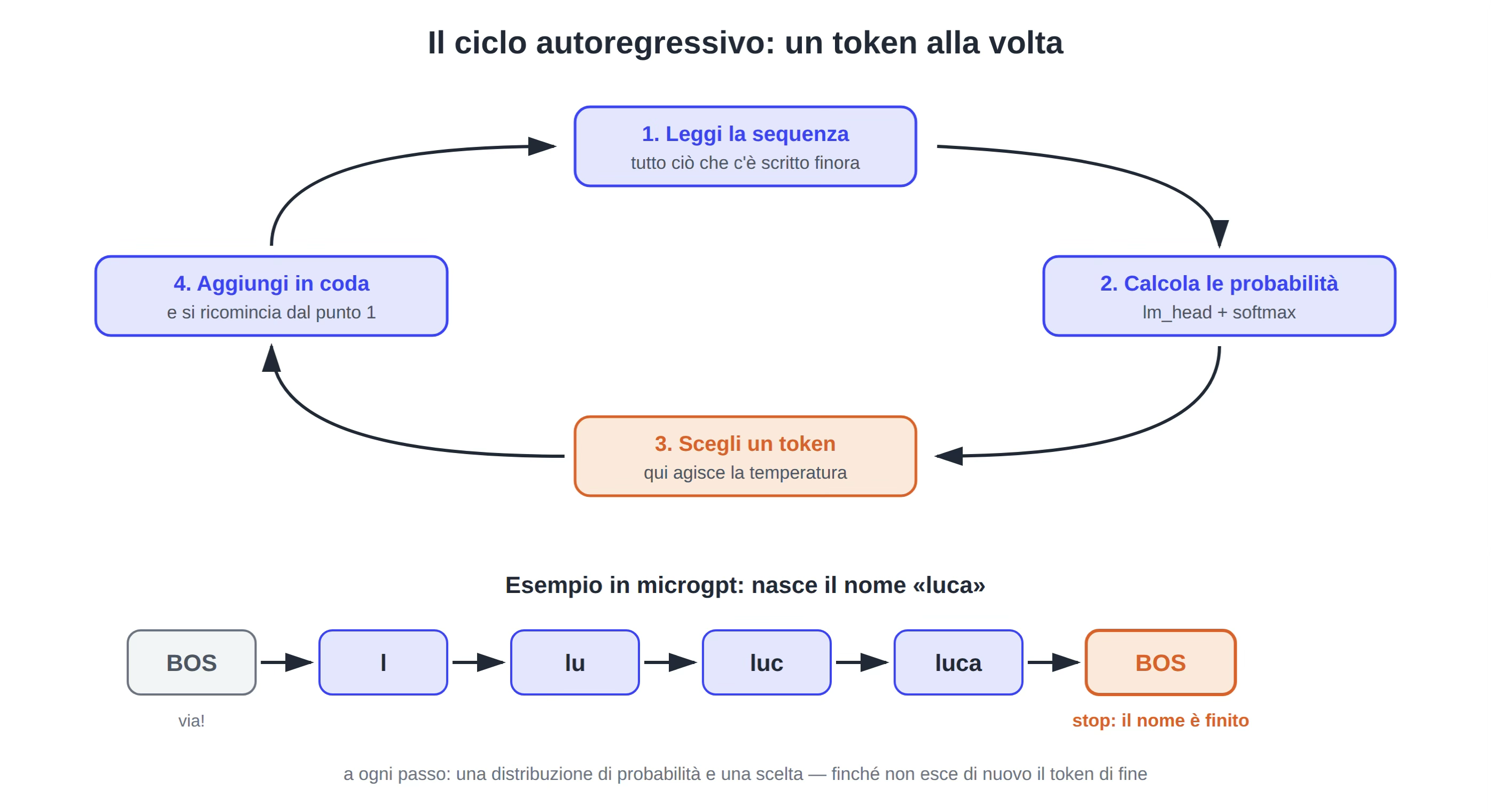
Figura 2: il ciclo autoregressivo — da BOS a “luca”, un token alla volta; il ciclo si chiude quando esce di nuovo il token di fine.
Perché il modello non vede il futuro (e perché l’output costa di più)
Quando il modello calcola l’attenzione per un token può guardare solo i token che lo precedono mai quelli che verranno. Questa si chiama causalità e durante l’addestramento il modello impara a prevedere la lettera successiva senza poterla sbirciare.
Nel codice di Karpathyle Key e i Value di ogni token (i “cartellini” e i “contenuti” dell’Articolo 3) vengono accumulati in due liste man mano che i token vengono processati.
Quando il modello ad esempio genera il token numero 50, l’attenzione deve confrontarlo con tutti i 49 token precedenti. Per farlo servono le Key e i Value di quei 49 token.
Ora quei vettori K e V erano già stati calcolati nei passi precedenti: al passo 49, al passo 48, e così via. Se non fossero salvati in memoria il modello dovrebbe ricalcolarli tutti da capo a ogni nuovo token (al passo 50 rifarebbe i conti per 49 token, 51 per 50 token, ecc).
Un lavoro enorme e completamente inutile perché il risultato sarebbe identico.
La KV cache è la decisione di conservare quei vettori in memoria invece di buttarli via: a ogni nuovo token si calcolano solo le K e V di quel token e si appendono alle due liste.
È la metafora di uno studente del primo anno di Università che prendeva appunti di Analisi I con il registratore perché non aveva le basi iniziali per capire: ascoltava una frase della registrazione e scriveva sul quadernone la nuova frase. Non riascoltava tutta la registrazione dall’inizio per scrivere la nuova frase (PS: 2 ore di registrazione delle lezioni di Analisi I corrispondevano a circa 6 ore di trascrizioni a mano successive).
Conservare la KV cache evita di ricalcolare da zero a ogni nuovo token e conserva in memoria tutto ciò che è già stato elaborato ed è il motivo per cui alcune API scontano i “token cached”.
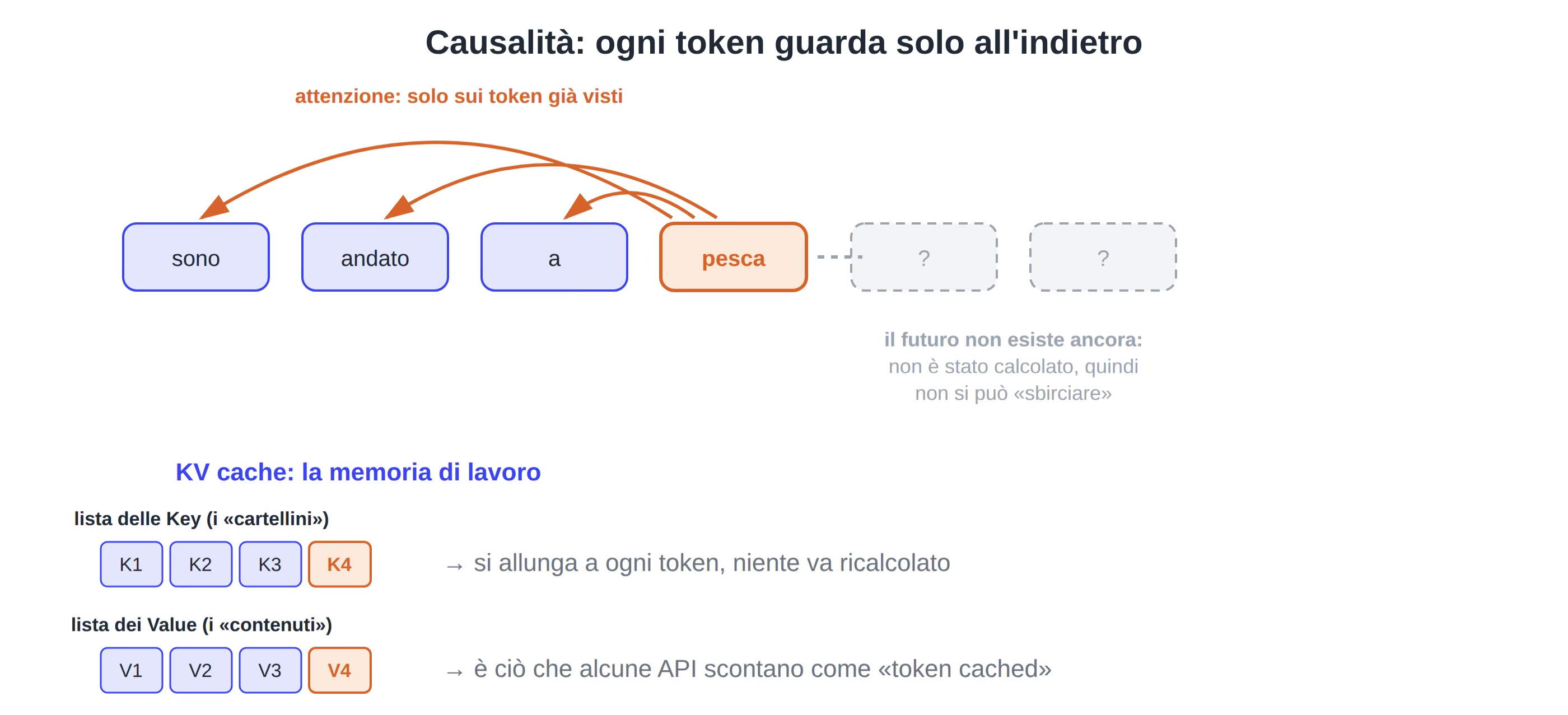
Figura 3 la causalità: ogni token presta attenzione solo a ciò che lo precede e la KV cache, le due liste che salvano la memoria di lavoro della generazione.
Da qui discende una conseguenza economica diretta, che spiega le fatture delle API:
ogni token in uscita richiede un giro completo di calcolo (attenzione su tutta la sequenza accumulata, feed-forward, lm_head, softmax), mentre i token in entrata vengono elaborati una volta sola, in blocco.
Per questo motivo i listini prezzi dei provider mostrano l’output tipicamente da 2 a 5 volte il prezzo dell’input.
Piccola Hint per risparmiare soldi:
Una pipeline che analizza 100 contratti al giorno chiede al modello: “leggi il contratto e dimmi cosa contiene”
Il modello risponde con una pagina di riassunto per ogni contratto: una pagina di output (la voce più cara del listino) moltiplicata per 100.
Cambiando il prompt in: “estrai solo penali, data di rinnovo e foro competente, in JSON”
il contratto in ingresso costa uguale ma la risposta passa da una pagina a tre righe: l’output si riduce di dieci volte, e con lui la fattura.
Stesso modello, stesso lavoro utile, costo molto più basso, solo perché si è chiesto al modello di scrivere di meno.
La temperatura: creatività o precisione
Nel momento in cui il modello arriva all’inferenza la scelta del token tra i vari token probabili è fortemente influenzata da un parametro: la temperatura.
Il modello non ha una sola risposta certa ma una lista di pezzi possibili, ciascuno con la sua probabilità. Per la scelta usa la la temperatura:
- Temperatura bassa (vicina a 0): le probabilità vengono “esasperate” e il modello prende quasi sempre il pezzo più probabile. Le risposte diventano prudenti, stabili, ripetibili: lo stesso prompt dà quasi sempre lo stesso risultato.
- Temperatura alta: la distribuzione si “appiattisce” e anche i pezzi meno probabili hanno una chance concreta. Le risposte diventano più varie e “creative” ma anche più imprevedibili e più esposte all’errore.
Facciamo l’esempio con la prima lettera di un nome generato da microgpt (valori indicativi):
| Lettera | Temperatura 0,2 | Temperatura 0,7 | Temperatura 1,0 (naturale) |
| l | 74% | 32% | 18% |
| m | 19% | 24% | 15% |
| a | 6% | 18% | 12% |
| z | ≈0% | 2% | 0,5% |
A temperatura bassa la lettera “l” che era solo la più probabile diventa quasi una certezza: escono sempre gli stessi nomi “sicuri”. A temperatura alta la “z” ogni tanto esce e con lei nomi più originali, ma anche qualche sequenza improbabile.
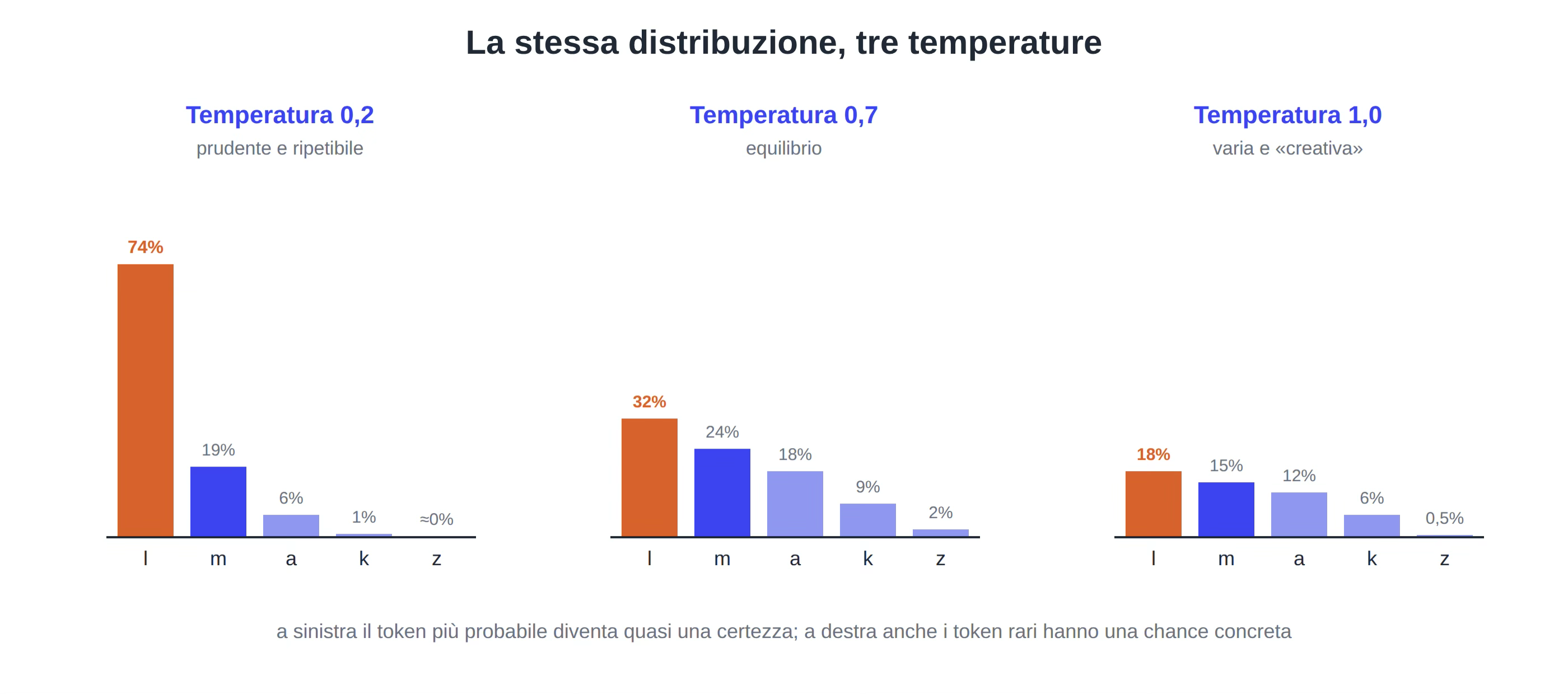
Figura 4: la stessa distribuzione di probabilità a tre temperature, bassa, piatta e alta.
Questo spiega un comportamento che mi disorientava: perché lo stesso modello con lo stesso prompt, a volte risponde in modo diverso? La temperatura.
Hint in casi pratici
in compiti aziendali in cui conta la coerenza, estrarre dati o classificare o produrre output da validare, in questo caso la temperatura va tenuta bassa. In uno scenario di scrittura fantasy invece va tenuta alta.
Ecco un esempio di chiamata api in python dove si setta la temperatura:
| response = client.messages.create( model=”claude-sonnet-4-6″, max_tokens=1000, temperature=0.2, messages=[{“role”: “user”, “content”: “Estrai le clausole in JSON…”}] ) |
Modello base vs modello instruct
Ecco raggiunto uno dei punti più interessanti: il modello descritto finota è addestrato solo a prevedere il pezzo successivo, questo modello prende il nome di modello base.
Un modello base non risponde alle domande: le tratta come un testo da proseguire.
Per il modello la domanda “Come ti chiami?” non è una richiesta rivolta a qualcuno ma una pagina interrotta a metà. Come detto finora il suo unico compito è scriverne il seguito più probabile.
Se si pone quella domanda ad un modello base una risposta plausibile potrebbe essere:“Quanti anni hai?”
perché nei testi che ha letto, dopo quella domanda spesso ne segue un’altra. Non sta cercando di aiutare, sta completando un testo.
Microgpt è un modello base: genera nomi, non dialoga.
Gli assistenti che usiamo ogni giorno partono da un modello base e poi aggiungono due passaggi che fanno la differenza:
- Supervised Fine-Tuning (SFT)
- Reinforcement Learning from Human Feedback (RLHF)
1. Supervised Fine-Tuning (SFT). Si prende il modello base e lo si addestra ancora un po’, ma su materiale di tipo diverso: non più testo grezzo preso dal web ma coppie domanda-risposta scritte e curate da esseri umani:
{“traduci questo testo” → la traduzione giusta;
“riassumi questo documento” → il riassunto}
Il meccanismo di apprendimento è identico a quello dell’Articolo 2 — loss, gradiente, Adam — cambia solo il menu.
Il modello che già sa comporre frasi sensate impara a che gioco sta giocando: seguire le istruzioni invece di limitarsi a proseguire il testo.
2. RLHF (Reinforcement Learning from Human Feedback). Di fronte a più risposte possibili del modello dei valutatori umani indicano quale preferiscono. Il modello viene spinto a produrre risposte in linea con quelle preferenze. Questo è il passaggio che partendo da GPT-3, ha portato a InstructGPT e poi alla prima versione di ChatGPT.
Il risultato è un modello instruct: stessa architettura, stessi embedding, stessa attention dei tre articoli precedenti ma con un comportamento assolutamente diverso. In basso la pipeline per arrivare ad un modello instruct partendo dal pre-training.
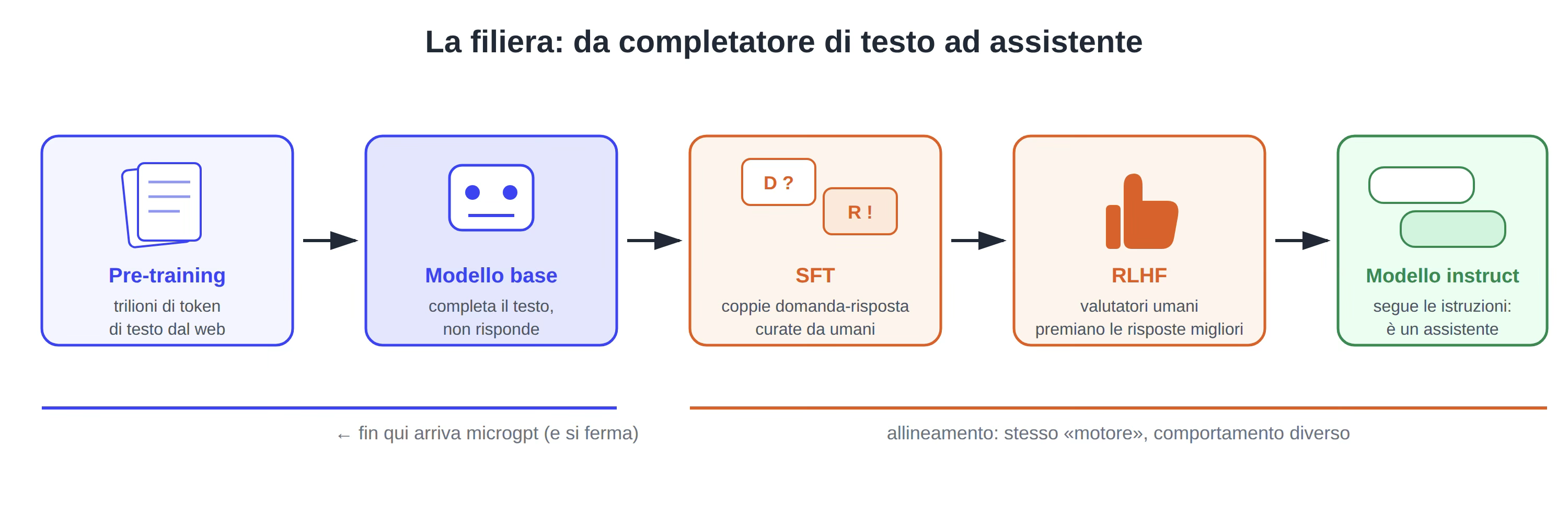
Figura 5 la filiera del modello instruct: pre-training → modello base → SFT → RLHF → modello instruct.
Ricapitolando: microgpt
Adesso abbiamo – in teoria – tutti gli strumenti per capire microgpt e riconoscere ogni blocco:
- Dataset e tokenizer: 32.000 nomi, le 26 lettere più il token di inizio/fine (Articoli 1 e 4).
- Autograd, loss, gradiente, Adam: il meccanismo con cui il modello impara dagli errori (Articolo 2).
- Embedding e positional encoding: da numeri-etichetta a vettori con significato e ordine (Articolo 3).
- Attention, feed-forward, residual, normalizzazione: il blocco transformer completo (Articolo 3).
- lm_head, softmax, ciclo autoregressivo, temperatura: la generazione, token dopo token (Articolo 4).
L’unica parte che microgpt non contiene è SFT e RLHF. Microgpt si ferma al modello base. La distanza tra microgpt e i modelli di frontiera è di ordini di grandezza in parametri, dati e calcolo ma l’algoritmo di fondo e questo.
Conclusioni
Un LLM è un modello base (un completatore statistico di pezzi di testo) costruito su embedding e attention e addestrato con il gradiente a cui si aggiunge uno strato di allineamento (SFT + RLHF) che lo trasforma in un assistente.
Un LLM è un “pappagallo stocastico”?
Dopo averlo smontato riga per riga la mia opinione è: No e tanti iniziano a smentire il concetto di pappagallo stocastico perché troppo riduttiva.
Il meccanismo di fondo è completamente statistico, quello sì ma un pappagallo ripete sequenze che ha sentito.
Qui abbiamo visto nascere qualcosa di diverso: una mappa geometrica del significato che nessuno ha progettato (Articolo 3), e un’attenzione che sposta il senso di “pesca” a seconda delle parole vicine. Ripetere non è questo.
Bisogna però non cadere nell’eccesso opposto: non è nemmeno “comprensione” nel senso umano forse una terza cosa che non è mai stata costruita e che conviene giudicare per quello che fa.
L’obiettivo di questo primo ciclo era uno solo: smettere di guardare all’IA come a una scatola magica. Chi conosce il meccanismo può anticipare i comportamenti del modello, le allucinazioni, la variabilità, i costi, invece di subirli.
Hint 1: quasi sempre conviene partire da un modello “instruct”, non da un “base”
Quasi nessuna startup dovrebbe partire da un modello base: significherebbe costruirsi in casa SFT e allineamento, un lavoro costoso e molto specialistico (dataset di istruzioni curati, valutatori umani, infrastruttura di training).
Nel 99% dei casi si parte da un modello instruct già allineato ed eventualmente lo si specializza con un fine-tuning sui propri dati, come visto nell’ Hint1 dell’Articolo 3.
Quando un fornitore propone un “modello su misura”, le domande da fare sono due: parte da un base o da un instruct? E cosa, esattamente, ci ha aggiunto?
Se le risposte sono vaghe il “su misura” è probabilmente solo un prompt ben scritto sopra un modello commerciale.
Hint 2: la temperatura è una leva di affidabilità non un dettaglio
Per i compiti in cui l’output deve essere coerente e verificabile (estrazione strutturata, classificazione, generazione di JSON da validare contro uno schema) la temperatura va impostata al minimo, e va scritto nel contratto con chi sviluppa: è un parametro della chiamata API, non una proprietà del modello.
La variabilità che in una demo sembra “intelligenza creativa” diventa in produzione una fonte di errori difficili da riprodurre e da correggere.
La temperatura si alza solo dove serve davvero: brainstorming, bozze di testo destinate alla revisione umana. È una leva gratuita: cambiarla non costa nulla, ignorarla può costare molto.
Ricordiamoci che i token in uscita costano più di quelli in entrata quindi vincolare la lunghezza delle risposte, con istruzioni esplicite o con il parametro dedicato delle API, equivale a risparmio.
Con questo numero si chiude lo smontaggio di microgpt: chi ha seguito i quattro articoli può ora aprire quelle 200 righe e riconoscerle una a una, dal tokenizer alla generazione dei nomi. Nel prossimo numero mettiamo subito a frutto il meccanismo con la domanda più concreta di tutte: quale modello scegliere: cloud, open-weight o locale per la propria azienda, tenendo conto di costi, GDPR e controllo dei dati (foto di Igor Omilaev su Unsplash).
© RIPRODUZIONE RISERVATA