
Indice degli argomenti
Prosegue la serie “Inside the machine” a cura di Giuseppe Ciuni. Nei primi quattro articoli abbiamo smontato microgpt, il GPT in circa 200 righe di Karpathy: cos’è un LLM, come impara, come rappresenta il significato e come arriva alla risposta. Ora sappiamo come funziona la macchina. Questo quinto articolo apre il ciclo pratico con la prima decisione vera: quale modello scegliere — cloud, open-weight o locale — tenendo conto di costi, GDPR e controllo dei dati.
I concetti che verranno introdotti in questo articolo sono i seguenti:
- le quattro modalità di deployment (cloud proprietario, open-weight self-hosted, locale, private cloud);
- le tre dimensioni della scelta (costo, dati e GDPR, controllo operativo);
- il punto di pareggio (a che volume il self-hosting costa meno del cloud);
- DS4 / DwarfStar (un modello quasi-frontiera che gira su un portatile).
Un CTO o un fondatore che integri l’IA nella propria azienda dovrà prima o poi rispondere a domande come queste:
- i miei dati possono uscire dall’azienda, sì o no?
- A che volume conviene smettere di pagare a consumo e mettere su un’infrastruttura mia?
- Quanto mi costa davvero gestire un modello in casa, oltre al prezzo della GPU?
Andiamo con ordine.
Dove eravamo rimasti
Con l’articolo 4 si è chiuso lo smontaggio di microgpt. Sappiamo cosa fa un LLM, come impara, come rappresenta il significato e come genera una risposta, un pezzo alla volta.
Finora però abbiamo guardato dentro la macchina. Adesso il problema cambia natura: non più “come funziona” ma “quale uso”. Ed è il primo bivio in cui sbagliare costa budget vero.
La prima domanda non è “quale modello”, ma “quali vincoli”
Ovviamente il marketing ci porterà a pensare: prendo il modello in cima ai benchmark e via.
A mio avviso questo è un approccio forse semplicistico; il marketing, se non introduce ragioni decisionali e basi su cui appoggiarsi, mi fa tornare in mente il seguente detto:
“La carni vanniata è menza vinnuta”
“La carne vanniata (=urlata per le strade dai venditori ambulanti) è mezza venduta dato che stimola le papille gustative delle persone che sentono l’urlo dalle proprie case in orario di pranzo”
Il modello più potente sulla carta è quasi sempre il più caro, il più difficile da controllare e quasi sempre sovradimensionato. Spesso è sufficiente un modello più piccolo ed economico rispetto a quello che il marketing suggerisce di comprare.
La domanda giusta non è “qual è il migliore” ma citando Will Smith nel film “Io Robot” nell’interazione con l’ologramma del Dott. Alfred Lanni, la domanda giusta è: “quale modalità di installazione/utilizzo va bene per i miei vincoli”.
Partendo dal vincolo “dati, budget, controllo” otteniamo un forte restringimento nella scelta del numeri di modelli potenziali da adottare. La qualità si guarda successivamente e dentro le opzioni rimaste.
Hint
La prima cosa da mettere nero su bianco nell’adozione di un modello non è quanto sia potente il modello ma quale risponde a questa domanda:
I miei dati possono uscire dall’azienda? Sì/No?
La risposta a questa domanda dimezza le opzioni di modelli da adottare prima ancora di aprire una classifica di modelli potenziali.
Informazione a latere: molte aziende, in questo periodo storico, hanno il problema della Shadow AI ossia il fenomeno in cui un dipendente dell’azienda usa la IA per svolgere i task assegnati, il tutto avviene all’insaputa dell’azienda creando falle di informazioni verso l’esterno.
Le quattro strade
I modi di mettere un LLM in produzione sono quattro. L’ordine seguito è dal massimo della comodità al massimo del controllo.
Primo metodo: API cloud proprietarie.
Uso dei modelli di frontiera OpenAI, Anthropic, Google ecc. A questi modelli si manda il testo ad un endpoint e si riceve una risposta (vedi figura 1)
Pro: zero infrastruttura, qualità di frontiera, online in un pomeriggio. Si pagano a token e il conto cresce con l’uso. In pratica integrarla è questione di poche righe.
Contro: i dati escono dall’azienda e finiscono sui server di un fornitore terzo, spesso fuori dall’UE.
Ecco una chiamata minima in Python di OpenAI:
| from openai import OpenAI client = OpenAI() # la chiave da OPENAI_API_KEY. Mi raccomando raga’ mai cablata # sul codice ma in file .env email = “””Buongiorno, ho effettuato l’ordine #4521 cinque giorni fa ma non è ancora arrivato. Potete dirmi quando lo riceverò? Grazie, Marco””” risposta = client.chat.completions.create( model=”gpt-4o-mini”, messages=[ {“role”: “system”, “content”: “Sei l’assistente del supporto clienti: rispondi alle email in modo cortese e conciso.”}, {“role”: “user”, “content”: email}, ], ) print(risposta.choices[0].message.content) |
Figura 1: Poche righe, zero infrastruttura: è il punto di forza del cloud ma è il punto esatto in cui i tuoi dati lascia la tua rete. Per dover di cronaca, queste poche righe di codice generano un messaggio di risposta a una mail ricevuta da parte di un cliente.
Secondo metodo: open-weight self-hosted.
Modelli con i pesi pubblici: Llama, Mistral, DeepSeek, Qwen, GLM da far girare su una propria infrastruttura hardware a noleggio.
Di solito si noleggia una GPU su AWS o Azure, e un proprio server cloud. Bisogna gestire in proprio il deployment. La macchina su cui gira il modello è fisicamente nel datacenter del fornitore.
La qualità attuale di questi modelli è buona per molti compiti e spesso confrontabile con i modelli proprietari.
Pro: controllo totale e costo fisso.
Contro: la gestione è totalmente a carico a nostro e di conseguenza gli aggiornamenti, la sicurezza, il monitoraggio sono bisogna farli in casa.
Terzo Metodo: locale / on-prem.
Gli stessi modelli con i pesi pubblici: Llama, Mistral, DeepSeek, Qwen, GLM, sul proprio hardware fisico, dentro il perimetro aziendale.
I modelli sono spesso quantizzati (“compressi” per girare su hardware più economico), con un piccolo calo di qualità (ne parlerò successivamente di questo argomento). I dati non lasciano mai l’edificio.
Pro: massimo controllo
Contro: costo iniziale dell’hardware per l’esecuzione del modello, prestazioni dipendenti dall’hardware.
Aggiornamento dell’ultimo periodo: da notare il progetto DS4 (DwarfStar 4), motore di inferenza open source di Salvatore Sanfilippo, aka Antirez.
DS4 è un motore costruito su misura per il modello open-weight, DeepSeek V4 Flash e a breve per GLM 5.2 e DeepSeek V4 Pro.
Con una quantizzazione asimmetrica (un mix di 2 e 8 bit) fa girare un modello di qualità quasi-frontiera su una macchina con 96/128 GB di memoria unificata VRAM (un MacBook Pro di fascia alta per intenderci o Nvidia DGX Spark) senza cloud e senza connessione.
È la dimostrazione pratica della tesi di questo articolo: il modello che ti serve può già stare sulla tua scrivania. Nel prossimo paragrafo un piccolo approfondimento su DS4.
Quarto Metodo: Private cloud / VPC.
La via di mezzo per la compliance. I modelli di frontiera offerti dentro un perimetro isolato e con garanzie contrattuali Azure OpenAI, Amazon Bedrock.
La qualità del cloud proprietario ma con la così detta “data residency” e clausole sul trattamento dei dati che il cloud pubblico “nudo” non ti dà.
Pro: costa più dell’API base
Contro: costa meno del self-hosting.
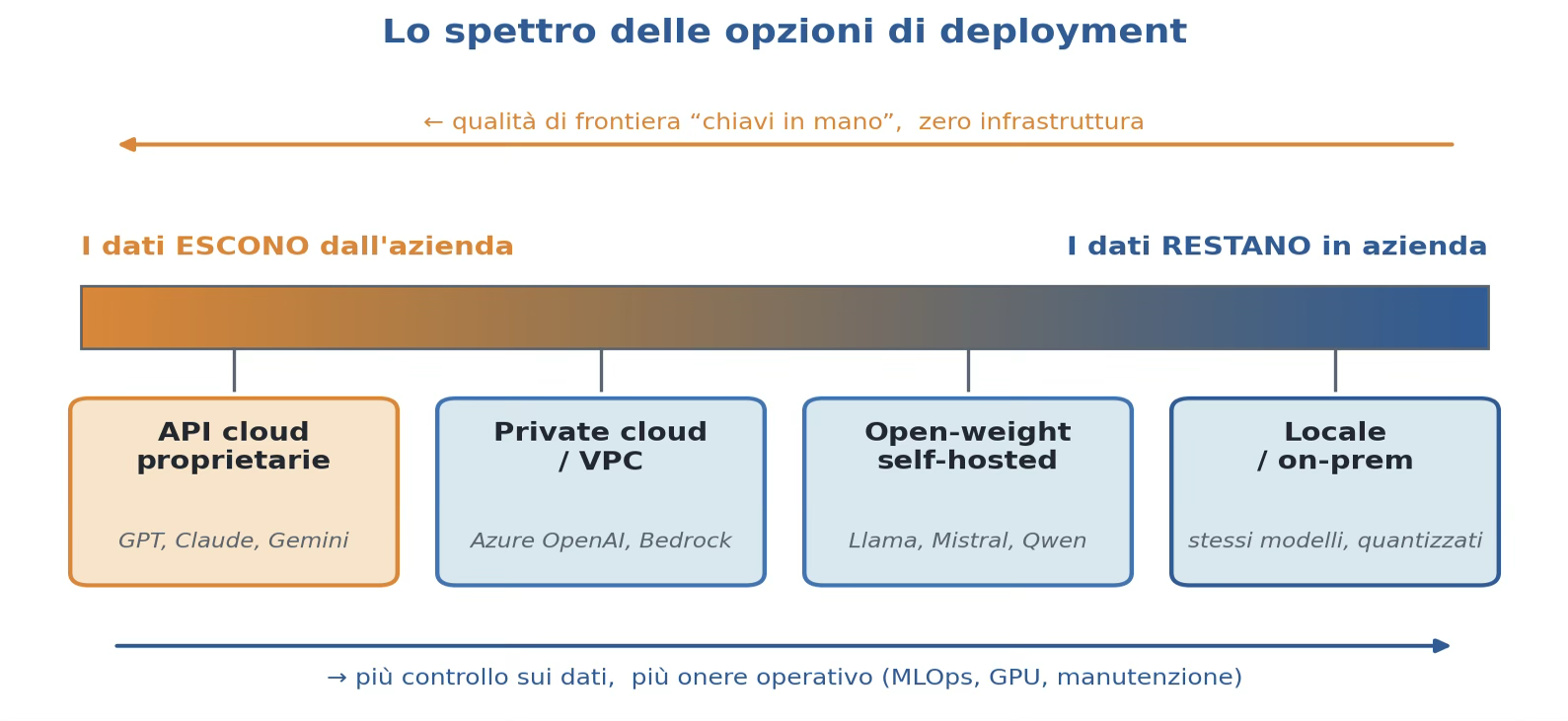
Figura 2 — Le quattro opzioni su un unico spettro: più controllo sui dati a destra, più comodità a sinistra.
Approfondimento su DS4: adesso l’IA di frontiera gira sul portatile
Vale la pena soffermarsi su DS4 (DwarfStar 4), dato che è la prova concreta di quanto detto finora: è un progetto open source di Salvatore Sanfilippo, aka Antirez, raggiungibile al seguente link: https://github.com/antirez/ds4.
DS4 non è un runtime di file GGUF generici (per dovere di cronaca, il GGUF è il formato file in cui si impacchetta un modello [pesi, tokenizer e metadati] per eseguirlo in locale), ma un esecutore fatto su misura per un solo modello open-weight, DeepSeek V4 Flash. A breve anche GLM 5.2.
Un modello alla volta (con la roadmap aperta). DeepSeek V4 Flash è un modello da 284 miliardi di parametri totali, 13 miliardi attivi per token e una finestra di contesto da un milione di token. Salvatore sta lavorando per far girare anche GLM 5.2 e sta facendo i primi esperimenti su DeepSeek V4 Pro, il fratello maggiore da 1,6 mila miliardi di parametri.
La quantizzazione asimmetrica è l’idea che rende DeepSeek V4 Flash eseguibile in locale il quale funziona grazie alla struttura del Mixture of Experts (MoE).
Il MoE divide il modello in tanti sotto-modelli specializzati chiamati “esperti“. Per ogni token un componente chiamato router ne attiva solo alcuni ignorando gli altri.
Questo crea una gerarchia naturale:
- alcune parti del modello lavorano su ogni token e sono quindi parti critiche: gli esperti condivisi, il router stesso e le matrici che trasformano il vettore di ogni parola da un passaggio al successivo (le moltiplicazioni che nell’articolo 3, generavano Query, Key e Value);
- gli esperti instradati invece entrano in gioco solo quando il router li chiama. Questi sono la maggior parte del peso del modello.
Da qui l’idea:
“Non è obbligatorio comprimere tutto allo stesso modo”
DS4 lascia in piena precisione le parti critiche (una quantizzazione troppo spinta degraderebbe la qualità del modello fino a generare allucinazioni importanti), mentre porta a 2 bit gli esperti instradati, dove anche se c’è approssimazione questa è tollerabile.
Facendo una quantizzazione aggressiva (una forma di compressione con perdita) proprio sulla fetta più pesante il peso crolla.
A piena precisione (in BF16 cioè 16 bit per ogni parametro), per far girare DeepSeek V4 Flash servirebbero circa 568 GB di memoria. Portando la quantizzazione degli esperti instradati a 2 bit, il file scende a 81 GB, perfetti per girare DeepSeek su un MacBook Pro di fascia alta.
Senza la struttura a esperti del MoE questo non sarebbe possibile: in un modello “denso” tutti i parametri lavorano su ogni token. In questa infrastruttura non c’è una parte “meno attiva” da sacrificare.
Come accennato prima ecco il risultato: con un MacBook Pro con 128 GB di memoria unificata il modello riesce a girare perfettamente. Molti utenti riferiscono che si riesce a eseguire il modello anche su un MacBook con 96 GB di memoria unificata.
La KV cache sul disco. L’altra intuizione riguarda la “memoria” della conversazione: la KV cache, cioè ciò che il modello ha già elaborato dei token precedenti per non doverli rileggere da zero a ogni parola nuova (la vedevamo nell’articolo 4).
Di solito la KV cache vive in RAM. DS4 la sposta su disco sfruttando gli SSD veloci dei portatili moderni.
Le conversazioni lunghe (che possono pesare diversi GB) vengono salvate e ricaricate senza rifare da capo il calcolo iniziale, il prefill.
Per chi usa un agente di coding che a ogni avvio manda un prompt iniziale enorme, significa non ripagare quel costo a ogni sessione. Questa parte l’avevamo trattata bene nell’articolo precedente.
Privacy e indipendenza dal cloud. Tutto in locale. DS4 espone un server compatibile con le API di OpenAI e Anthropic quindi basta configurare Claude Code o opencode e farli puntare al server DS4: in questo modo i coding agent lavorano senza problemi interagendo con DS4 e quindi con DeepSeek.
DS4 non è un prodotto finito ma come dimostrazione vale moltissimo: l’opzione “locale” di un modello quasi-frontiera che può stare sulla scrivania di casa.
Per qualche motivo mi tornano in mente gli esperimenti che facevamo con i miei amici durante l’adolescenza. Per far girare “Alone in the Dark”(un gioco con requisiti importanti per l’epoca e soprattutto per il mio PC) ci chiudevamo nella mia stanzetta per pomeriggi interi, l’obiettivo era di far partire quel gioco su un hardware che non ce la faceva.
Dopo un mare di tentativi alla fine ci siamo riusciti: usammo il floppy da 3,5 e quello da 5,25 pollici come memoria aggiuntiva oltre alla RAM del PC.
Le prestazioni erano discutibili ma funzionava e per noi è stato un risultato importante.
Da base a instruct: SFT e RLHF
Quando si scarica un openweight torna un bivio già visto nell’articolo 4. Il modello appena uscito dal pre-training (la versione base) sa solo completare testo. Per trasformarlo in un assistente che segue le istruzioni servono due passaggi: prima l’SFT e successivamente l’RLHF.
SFT — Supervised Fine-Tuning. Si addestra ancora il modello ma su materiale diverso: non più testo grezzo del web ma coppie «istruzione risposta giusta» scritte e curate da persone.
Il meccanismo di apprendimento è lo stesso dell’articolo 2 (loss, gradiente, Adam): cambia solo il menu.
Così il modello impara seguendo le istruzioni invece di proseguire il testo.
Un dataset di SFT, in concreto, è fatto di esempi come questi:
| ISTRUZIONE: Traduci in inglese: “Spedizione gratuita sopra i 50 euro” RISPOSTA: Free shipping on orders over 50 euros ISTRUZIONE: Riassumi in una riga il reclamo del cliente. RISPOSTA: Il cliente ha ricevuto un prodotto danneggiato e chiede il reso. ISTRUZIONE: Estrai la data di scadenza dal contratto (formato AAAA-MM-GG). RISPOSTA: 2027-03-31 |
Figura 3: Migliaia di coppie come queste insegnano al modello il formato e il tono attesi. Qui la qualità degli esempi conta più della quantità.
RLHF — Reinforcement Learning from Human Feedback. Con l’SFT il modello ha imparato il formato ma purtroppo non basta. Ecco il problema:
Tra due risposte entrambe corrette, quale è più chiara, più utile e più sicura? Questo l’SFT non lo insegna.
Ci pensa l’RLHF, in tre step successivi:
- si raccolgono le preferenze. Allo stesso prompt il modello produce due risposte. Una persona indica quale preferisce.
Si ripete su decine di migliaia di casi: nasce un dataset non di «risposte giuste», ma di «questa è meglio di quella»; - si addestra il reward model. Il modello attribuisce un voto ad una risposta;
- si ottimizza il modello. Il modello instruct genera, il reward model vota e un algoritmo di reinforcement learning (di solito PPO) spinge il modello verso le risposte con voto più alto.
In una frase: il modello impara a piacere al giudice (vedi figura 4).
Cos’è il reward model
È un secondo modello, con un solo compito: dare un voto a una risposta ossia un numero che stima quanto piacerebbe a un umano.
Non genera testo, lo giudica. Lo si addestra proprio sui confronti del primo passo ossia le preferenze: deve assegnare voto più alto alla risposta che le persone hanno preferito.
Una volta pronto, il reward model è un giudice automatico: può valutare milioni di risposte senza più un umano nel ciclo.
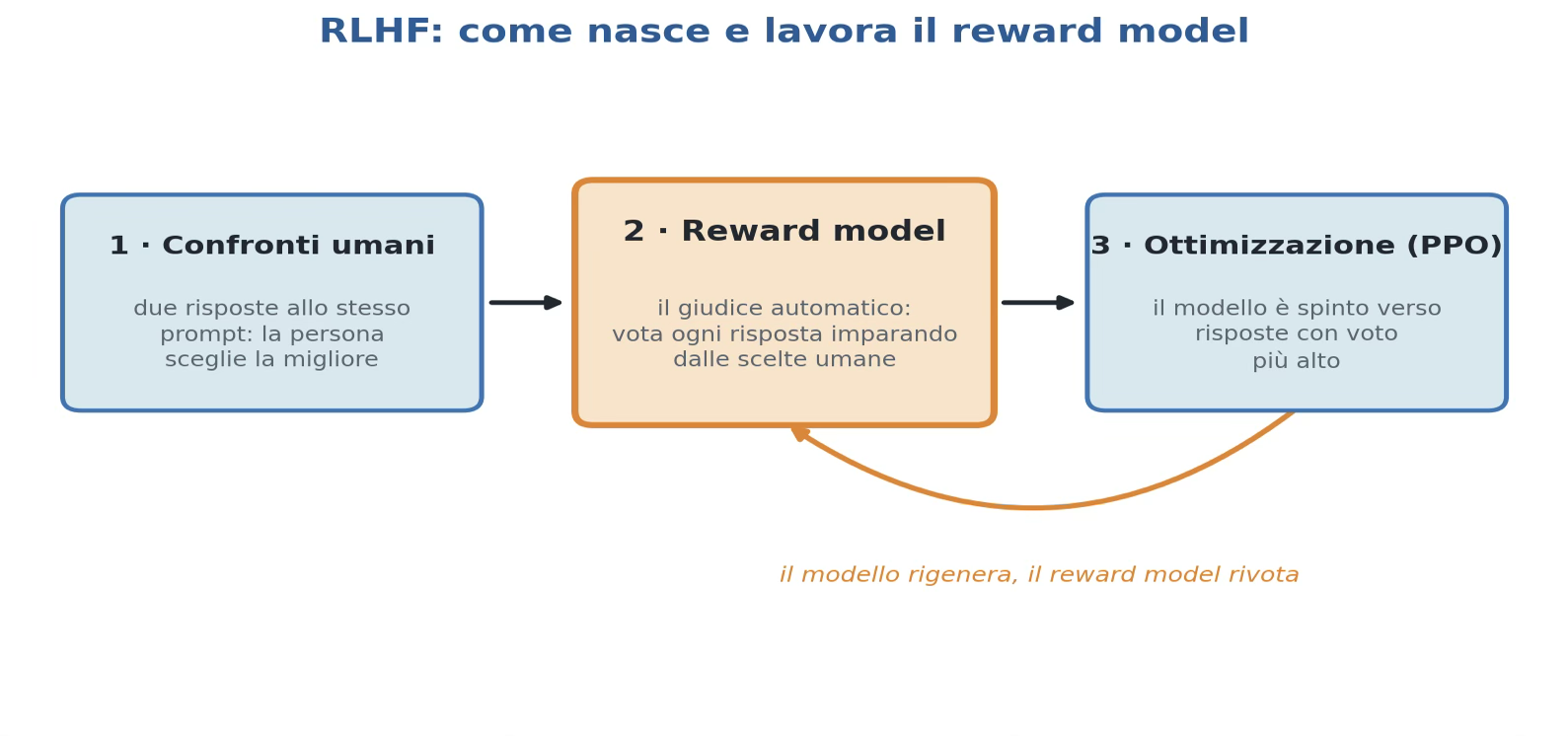
Figura 4 — L’RLHF in tre passi: dai confronti umani nasce il reward model (il “giudice”), che poi vota le risposte e guida l’ottimizzazione del modello.
L’insidia: il reward hacking. C’è un rovescio della medaglia, il modello non viene addestrato a essere utile ma ad ottenere voti alti dal reward model. Il giudice (il reward model) tende a premiare le risposte lunghe, quelle che danno ragione all’utente, quelle dal tono sicuro.
A furia di tentativi il modello scopre queste preferenze e impara a sfruttarle: produce ciò che fa alzare il voto e non ciò che serve davvero. Questo non è voluto ma è un effetto collaterale dell’ottimizzazione: il modello sta solo massimizzando la sua ricompensa.
Il reward hacking è ancora un problema aperto
Le tre dimensioni che decidono
Dietro la scelta di un modello ci sono solo tre variabili. Tutto il resto è dettaglio.
Costo. Il cloud è a consumo: zero costo iniziale ma ogni richiesta si paga, ed il conto cresce con i volumi.
Il self-hosting è a costo fisso: paghi molto all’inizio (GPU, setup) e poco per ogni richiesta.
Dati e GDPR. “I dati escono” non è un modo di dire. Si trasferiscono fisicamente informazioni a un fornitore esterno e spesso extra-UE.
In termini GDPR si diventa titolare del trattamento dei dati di un servizio e il fornitore è responsabile. In questo caso serve un accordo sul trattamento (DPA) e va verificata la data residency.
Per sanità, ambito legale e bancario il cloud pubblico può essere percorribile in maniera molto arzigogolata.
Controllo. Col cloud non si ha manutenzione ma si è legati alle scelte del fornitore: prezzi, modelli ritirati, limiti. Questo si chiama Lock-in.
Col self-hosting si ha il controllo totale e di conseguenza la fatica. Più controllo più onere!
Quanto costa davvero: il punto di pareggio
Non c’è una risposta valida sempre: dipende da quanto userai il modello (vedi figura 5).
Per pochi utilizzi o fretta di partire meglio il cloud. Per tanti utilizzi stabili o dati che non possono uscire meglio self-hosting.
Un helpdesk con poche migliaia di richieste al mese di solito sta meglio sul cloud. Lo stesso helpdesk con centinaia di migliaia di richieste stabili meglio una GPU dedicata

Figura 5 — Pochi utilizzi: meglio il cloud, paghi solo quando usi. Tanti utilizzi: meglio il self-hosting, l’infrastruttura si ripaga. Il pareggio dipende dal tuo volume.
Un caso reale: la banca
Un istituto bancario doveva permettere ai propri operatori di interrogare in linguaggio naturale centinaia di documenti interni:circolari, contratti, normative. Sulla carta un caso da manuale: API cloud di frontiera. Si avrebbe avuto qualità massima, nessuna infrastruttura ed online in poche settimane.
Non se ne fece nulla: quei documenti contenevano dati che per policy interna non potevano lasciare il perimetro della banca.
La domanda “i dati possono uscire?” aveva risposta “no”!
Si è scelto un modello open-weight self-hosted dentro l’infrastruttura della banca.
La matrice decisionale
Prendiamo gli assi cartesiani, nelle ascisse il volume/budget: quanto verrà usato il modello. Nelle ordinate la sensibilità dei dati: quanto è critico che non escano. Vedi figura 6.
Dati poco sensibili e volume basso: API cloud. Partenza rapida e pagamento a consumo, perfetto per un MVP
Dati poco sensibili, volume alto: self-hosting open-weight. Quando i volumi crescono e restano stabili, costa meno del cloud.
Dati sensibili, volume basso: private cloud. Qualità di frontiera con garanzie sui dati senza ancora un’infrastruttura propria.
Dati sensibili, volume alto: open-weight self-hosted o on-prem. Controllo totale e costo marginale basso. È il quadrante della banca.
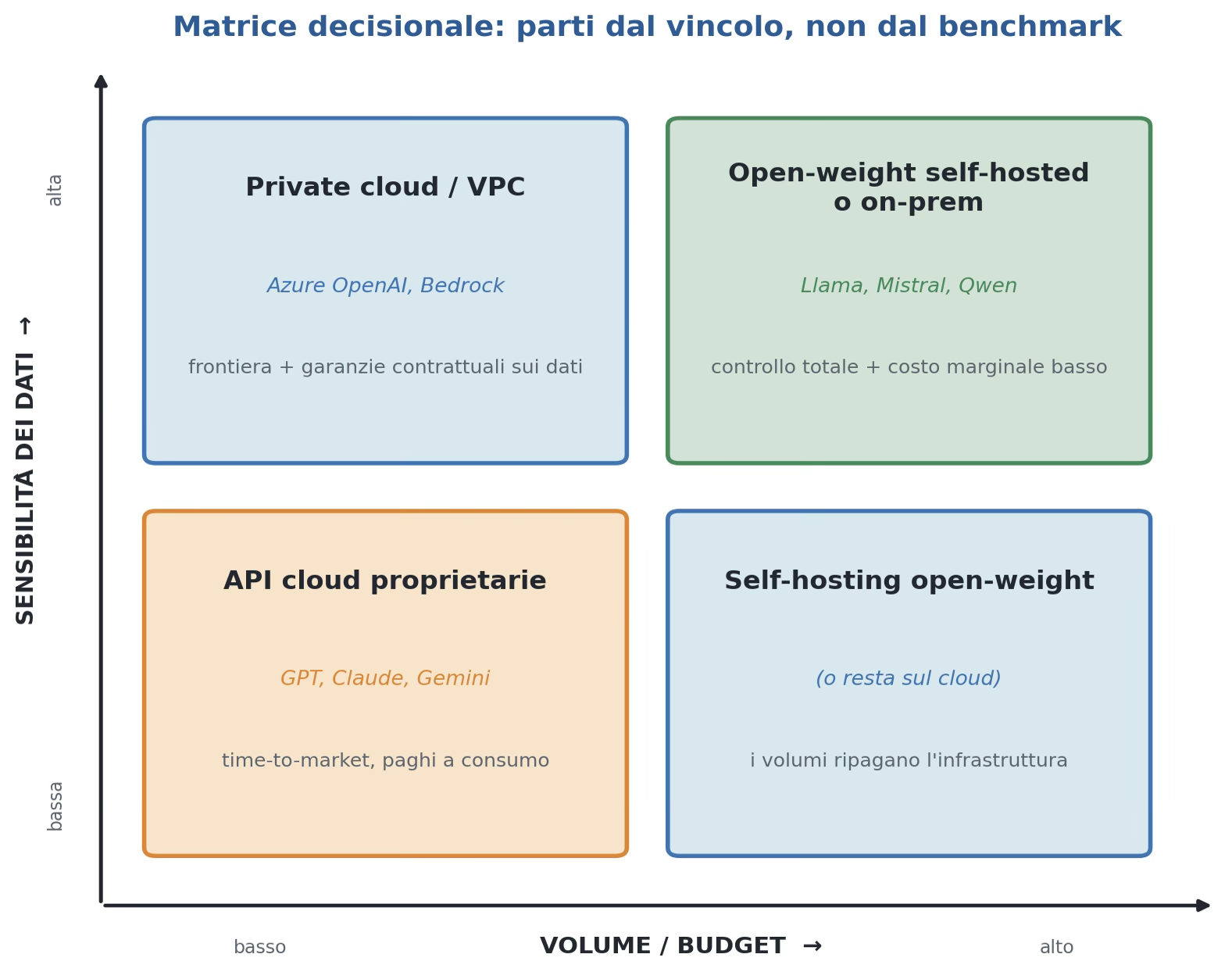
Figura 6 — La matrice decisionale: sensibilità dei dati × volume/budget. Il vincolo dominante ti porta nel quadrante, prima del benchmark.
Conclusioni
Chi parte dal benchmark compra potenza che spesso non gli serve e accetta vincoli che magari non può permettersi.
Chi parte dal vincolo arriva quasi sempre a un modello più piccolo, più economico e più adatto del primo della classe. Progetti come DS4.
Hint 1 — Bisogna partire dal vincolo, non dal benchmark
Quando un fornitore propone “il modello migliore”, la prima domanda non è quanto è potente, ma: i miei dati possono uscire dall’azienda? E poi: che volume ho, stabile o variabile?
Quelle risposte ti collocano in un quadrante della matrice prima di aprire qualsiasi classifica. Se il fornitore insiste sul benchmark e glissa sui dati, stai parlando con un venditore, non con un tecnico.
Hint 2 — Misura prima di investire (e tieniti una via d’uscita)
Prima di comprare GPU fai un pilota reale di due settimane su un’API a consumo e guarda la bolletta vera: il costo stimato a tavolino e quello misurato divergono quasi sempre e solo il secondo ti dice se il pareggio col self-hosting è vicino o lontano.
E ricorda che il costo del self-hosting non è solo la GPU: sono aggiornamenti, sicurezza, monitoraggio, persone e tempo.
Il rovescio del cloud è il lock-in: prevedi un’exit strategy (astrazione del provider, formati portabili) prima di legarti. (foto di Igor Omilaev su Unsplash)
© RIPRODUZIONE RISERVATA
